mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-07-14 07:39:15 +02:00
Merge remote-tracking branch 'origin/docs_and_minor_fixes' into model-zoo
# Conflicts: # README.md # train/README.md
This commit is contained in:
commit
0d84e7da16
8 changed files with 289 additions and 138 deletions
159
README.md
159
README.md
|
|
@ -2,6 +2,7 @@
|
||||||
|
|
||||||
> Document Layout Analysis, Binarization and OCR with Deep Learning and Heuristics
|
> Document Layout Analysis, Binarization and OCR with Deep Learning and Heuristics
|
||||||
|
|
||||||
|
[](https://pypi.python.org/pypi/eynollah)
|
||||||
[](https://pypi.org/project/eynollah/)
|
[](https://pypi.org/project/eynollah/)
|
||||||
[](https://github.com/qurator-spk/eynollah/actions/workflows/test-eynollah.yml)
|
[](https://github.com/qurator-spk/eynollah/actions/workflows/test-eynollah.yml)
|
||||||
[](https://github.com/qurator-spk/eynollah/actions/workflows/build-docker.yml)
|
[](https://github.com/qurator-spk/eynollah/actions/workflows/build-docker.yml)
|
||||||
|
|
@ -11,24 +12,22 @@
|
||||||

|

|
||||||
|
|
||||||
## Features
|
## Features
|
||||||
* Support for 10 distinct segmentation classes:
|
* Document layout analysis using pixelwise segmentation models with support for 10 segmentation classes:
|
||||||
* background, [page border](https://ocr-d.de/en/gt-guidelines/trans/lyRand.html), [text region](https://ocr-d.de/en/gt-guidelines/trans/lytextregion.html#textregionen__textregion_), [text line](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextLineType.html), [header](https://ocr-d.de/en/gt-guidelines/trans/lyUeberschrift.html), [image](https://ocr-d.de/en/gt-guidelines/trans/lyBildbereiche.html), [separator](https://ocr-d.de/en/gt-guidelines/trans/lySeparatoren.html), [marginalia](https://ocr-d.de/en/gt-guidelines/trans/lyMarginalie.html), [initial](https://ocr-d.de/en/gt-guidelines/trans/lyInitiale.html), [table](https://ocr-d.de/en/gt-guidelines/trans/lyTabellen.html)
|
* background, [page border](https://ocr-d.de/en/gt-guidelines/trans/lyRand.html), [text region](https://ocr-d.de/en/gt-guidelines/trans/lytextregion.html#textregionen__textregion_), [text line](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextLineType.html), [header](https://ocr-d.de/en/gt-guidelines/trans/lyUeberschrift.html), [image](https://ocr-d.de/en/gt-guidelines/trans/lyBildbereiche.html), [separator](https://ocr-d.de/en/gt-guidelines/trans/lySeparatoren.html), [marginalia](https://ocr-d.de/en/gt-guidelines/trans/lyMarginalie.html), [initial](https://ocr-d.de/en/gt-guidelines/trans/lyInitiale.html), [table](https://ocr-d.de/en/gt-guidelines/trans/lyTabellen.html)
|
||||||
* Support for various image optimization operations:
|
|
||||||
* cropping (border detection), binarization, deskewing, dewarping, scaling, enhancing, resizing
|
|
||||||
* Textline segmentation to bounding boxes or polygons (contours) including for curved lines and vertical text
|
* Textline segmentation to bounding boxes or polygons (contours) including for curved lines and vertical text
|
||||||
* Text recognition (OCR) using either CNN-RNN or Transformer models
|
* Document image binarization with pixelwise segmentation or hybrid CNN-Transformer models
|
||||||
* Detection of reading order (left-to-right or right-to-left) using either heuristics or trainable models
|
* Text recognition (OCR) with CNN-RNN or TrOCR models
|
||||||
|
* Detection of reading order (left-to-right or right-to-left) using heuristics or trainable models
|
||||||
* Output in [PAGE-XML](https://github.com/PRImA-Research-Lab/PAGE-XML)
|
* Output in [PAGE-XML](https://github.com/PRImA-Research-Lab/PAGE-XML)
|
||||||
* [OCR-D](https://github.com/qurator-spk/eynollah#use-as-ocr-d-processor) interface
|
* [OCR-D](https://github.com/qurator-spk/eynollah#use-as-ocr-d-processor) interface
|
||||||
|
|
||||||
:warning: Development is focused on achieving the best quality of results for a wide variety of historical
|
:warning: Development is focused on achieving the best quality of results for a wide variety of historical
|
||||||
documents and therefore processing can be very slow. We aim to improve this, but contributions are welcome.
|
documents using a combination of multiple deep learning models and heuristics; therefore processing can be slow.
|
||||||
|
|
||||||
## Installation
|
## Installation
|
||||||
|
|
||||||
Python `3.8-3.11` with Tensorflow `<2.13` on Linux are currently supported.
|
Python `3.8-3.11` with Tensorflow `<2.13` on Linux are currently supported.
|
||||||
|
For (limited) GPU support the CUDA toolkit needs to be installed.
|
||||||
For (limited) GPU support the CUDA toolkit needs to be installed. A known working config is CUDA `11` with cuDNN `8.6`.
|
A working config is CUDA `11.8` with cuDNN `8.6`.
|
||||||
|
|
||||||
You can either install from PyPI
|
You can either install from PyPI
|
||||||
|
|
||||||
|
|
@ -53,31 +52,41 @@ pip install "eynollah[OCR]"
|
||||||
make install EXTRAS=OCR
|
make install EXTRAS=OCR
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### Docker
|
||||||
|
|
||||||
|
Use
|
||||||
|
|
||||||
|
```
|
||||||
|
docker pull ghcr.io/qurator-spk/eynollah:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
When using Eynollah with Docker, see [`docker.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/docker.md).
|
||||||
|
|
||||||
## Models
|
## Models
|
||||||
|
|
||||||
Pretrained models can be downloaded from [zenodo](https://doi.org/10.5281/zenodo.17194823) or [huggingface](https://huggingface.co/SBB?search_models=eynollah).
|
Pretrained models can be downloaded from [Zenodo](https://zenodo.org/records/17194824) or [Hugging Face](https://huggingface.co/SBB?search_models=eynollah).
|
||||||
|
|
||||||
For documentation on models, have a look at [`models.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/models.md).
|
For model documentation and model cards, see [`models.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/models.md).
|
||||||
Model cards are also provided for our trained models.
|
|
||||||
|
|
||||||
## Training
|
## Training
|
||||||
|
|
||||||
In case you want to train your own model with Eynollah, see the
|
To train your own model with Eynollah, see [`train.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/train.md) and use the tools in the [`train`](https://github.com/qurator-spk/eynollah/tree/main/train) folder.
|
||||||
documentation in [`train.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/train.md) and use the
|
|
||||||
tools in the [`train` folder](https://github.com/qurator-spk/eynollah/tree/main/train).
|
|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
Eynollah supports five use cases: layout analysis (segmentation), binarization,
|
Eynollah supports five use cases:
|
||||||
image enhancement, text recognition (OCR), and reading order detection.
|
1. [layout analysis (segmentation)](#layout-analysis),
|
||||||
|
2. [binarization](#binarization),
|
||||||
|
3. [image enhancement](#image-enhancement),
|
||||||
|
4. [text recognition (OCR)](#ocr), and
|
||||||
|
5. [reading order detection](#reading-order-detection).
|
||||||
|
|
||||||
|
Some example outputs can be found in [`examples.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/examples.md).
|
||||||
|
|
||||||
### Layout Analysis
|
### Layout Analysis
|
||||||
|
|
||||||
The layout analysis module is responsible for detecting layout elements, identifying text lines, and determining reading
|
The layout analysis module is responsible for detecting layout elements, identifying text lines, and determining reading
|
||||||
order using either heuristic methods or a [pretrained reading order detection model](https://github.com/qurator-spk/eynollah#machine-based-reading-order).
|
order using heuristic methods or a [pretrained model](https://github.com/qurator-spk/eynollah#machine-based-reading-order).
|
||||||
|
|
||||||
Reading order detection can be performed either as part of layout analysis based on image input, or, currently under
|
|
||||||
development, based on pre-existing layout analysis results in PAGE-XML format as input.
|
|
||||||
|
|
||||||
The command-line interface for layout analysis can be called like this:
|
The command-line interface for layout analysis can be called like this:
|
||||||
|
|
||||||
|
|
@ -91,29 +100,42 @@ eynollah layout \
|
||||||
|
|
||||||
The following options can be used to further configure the processing:
|
The following options can be used to further configure the processing:
|
||||||
|
|
||||||
| option | description |
|
| option | description |
|
||||||
|-------------------|:-------------------------------------------------------------------------------|
|
|-------------------|:--------------------------------------------------------------------------------------------|
|
||||||
| `-fl` | full layout analysis including all steps and segmentation classes |
|
| `-fl` | full layout analysis including all steps and segmentation classes (recommended) |
|
||||||
| `-light` | lighter and faster but simpler method for main region detection and deskewing |
|
| `-light` | lighter and faster but simpler method for main region detection and deskewing (recommended) |
|
||||||
| `-tll` | this indicates the light textline and should be passed with light version |
|
| `-tll` | this indicates the light textline and should be passed with light version (recommended) |
|
||||||
| `-tab` | apply table detection |
|
| `-tab` | apply table detection |
|
||||||
| `-ae` | apply enhancement (the resulting image is saved to the output directory) |
|
| `-ae` | apply enhancement (the resulting image is saved to the output directory) |
|
||||||
| `-as` | apply scaling |
|
| `-as` | apply scaling |
|
||||||
| `-cl` | apply contour detection for curved text lines instead of bounding boxes |
|
| `-cl` | apply contour detection for curved text lines instead of bounding boxes |
|
||||||
| `-ib` | apply binarization (the resulting image is saved to the output directory) |
|
| `-ib` | apply binarization (the resulting image is saved to the output directory) |
|
||||||
| `-ep` | enable plotting (MUST always be used with `-sl`, `-sd`, `-sa`, `-si` or `-ae`) |
|
| `-ep` | enable plotting (MUST always be used with `-sl`, `-sd`, `-sa`, `-si` or `-ae`) |
|
||||||
| `-eoi` | extract only images to output directory (other processing will not be done) |
|
| `-eoi` | extract only images to output directory (other processing will not be done) |
|
||||||
| `-ho` | ignore headers for reading order dectection |
|
| `-ho` | ignore headers for reading order dectection |
|
||||||
| `-si <directory>` | save image regions detected to this directory |
|
| `-si <directory>` | save image regions detected to this directory |
|
||||||
| `-sd <directory>` | save deskewed image to this directory |
|
| `-sd <directory>` | save deskewed image to this directory |
|
||||||
| `-sl <directory>` | save layout prediction as plot to this directory |
|
| `-sl <directory>` | save layout prediction as plot to this directory |
|
||||||
| `-sp <directory>` | save cropped page image to this directory |
|
| `-sp <directory>` | save cropped page image to this directory |
|
||||||
| `-sa <directory>` | save all (plot, enhanced/binary image, layout) to this directory |
|
| `-sa <directory>` | save all (plot, enhanced/binary image, layout) to this directory |
|
||||||
|
| `-thart` | threshold of artifical class in the case of textline detection. The default value is 0.1 |
|
||||||
|
| `-tharl` | threshold of artifical class in the case of layout detection. The default value is 0.1 |
|
||||||
|
| `-ocr` | do ocr |
|
||||||
|
| `-tr` | apply transformer ocr. Default model is a CNN-RNN model |
|
||||||
|
| `-bs_ocr` | ocr inference batch size. Default bs for trocr and cnn_rnn models are 2 and 8 respectively |
|
||||||
|
| `-ncu` | upper limit of columns in document image |
|
||||||
|
| `-ncl` | lower limit of columns in document image |
|
||||||
|
| `-slro` | skip layout detection and reading order |
|
||||||
|
| `-romb` | apply machine based reading order detection |
|
||||||
|
| `-ipe` | ignore page extraction |
|
||||||
|
|
||||||
|
|
||||||
If no further option is set, the tool performs layout detection of main regions (background, text, images, separators
|
If no further option is set, the tool performs layout detection of main regions (background, text, images, separators
|
||||||
and marginals).
|
and marginals).
|
||||||
The best output quality is achieved when RGB images are used as input rather than greyscale or binarized images.
|
The best output quality is achieved when RGB images are used as input rather than greyscale or binarized images.
|
||||||
|
|
||||||
|
Additional documentation can be found in [`usage.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/usage.md).
|
||||||
|
|
||||||
### Binarization
|
### Binarization
|
||||||
|
|
||||||
The binarization module performs document image binarization using pretrained pixelwise segmentation models.
|
The binarization module performs document image binarization using pretrained pixelwise segmentation models.
|
||||||
|
|
@ -124,9 +146,12 @@ The command-line interface for binarization can be called like this:
|
||||||
eynollah binarization \
|
eynollah binarization \
|
||||||
-i <single image file> | -di <directory containing image files> \
|
-i <single image file> | -di <directory containing image files> \
|
||||||
-o <output directory> \
|
-o <output directory> \
|
||||||
-m <directory containing model files> \
|
-m <directory containing model files>
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### Image Enhancement
|
||||||
|
TODO
|
||||||
|
|
||||||
### OCR
|
### OCR
|
||||||
|
|
||||||
The OCR module performs text recognition using either a CNN-RNN model or a Transformer model.
|
The OCR module performs text recognition using either a CNN-RNN model or a Transformer model.
|
||||||
|
|
@ -138,12 +163,29 @@ eynollah ocr \
|
||||||
-i <single image file> | -di <directory containing image files> \
|
-i <single image file> | -di <directory containing image files> \
|
||||||
-dx <directory of xmls> \
|
-dx <directory of xmls> \
|
||||||
-o <output directory> \
|
-o <output directory> \
|
||||||
-m <directory containing model files> | --model_name <path to specific model> \
|
-m <directory containing model files> | --model_name <path to specific model>
|
||||||
```
|
```
|
||||||
|
|
||||||
### Machine-based-reading-order
|
The following options can be used to further configure the ocr processing:
|
||||||
|
|
||||||
The machine-based reading-order module employs a pretrained model to identify the reading order from layouts represented in PAGE-XML files.
|
| option | description |
|
||||||
|
|-------------------|:-------------------------------------------------------------------------------------------|
|
||||||
|
| `-dib` | directory of binarized images (file type must be '.png'), prediction with both RGB and bin |
|
||||||
|
| `-doit` | directory for output images rendered with the predicted text |
|
||||||
|
| `--model_name` | file path to use specific model for OCR |
|
||||||
|
| `-trocr` | use transformer ocr model (otherwise cnn_rnn model is used) |
|
||||||
|
| `-etit` | export textline images and text in xml to output dir (OCR training data) |
|
||||||
|
| `-nmtc` | cropped textline images will not be masked with textline contour |
|
||||||
|
| `-bs` | ocr inference batch size. Default batch size is 2 for trocr and 8 for cnn_rnn models |
|
||||||
|
| `-ds_pref` | add an abbrevation of dataset name to generated training data |
|
||||||
|
| `-min_conf` | minimum OCR confidence value. OCR with textline conf lower than this will be ignored |
|
||||||
|
|
||||||
|
|
||||||
|
### Reading Order Detection
|
||||||
|
Reading order detection can be performed either as part of layout analysis based on image input, or, currently under
|
||||||
|
development, based on pre-existing layout analysis data in PAGE-XML format as input.
|
||||||
|
|
||||||
|
The reading order detection module employs a pretrained model to identify the reading order from layouts represented in PAGE-XML files.
|
||||||
|
|
||||||
The command-line interface for machine based reading order can be called like this:
|
The command-line interface for machine based reading order can be called like this:
|
||||||
|
|
||||||
|
|
@ -155,36 +197,9 @@ eynollah machine-based-reading-order \
|
||||||
-o <output directory>
|
-o <output directory>
|
||||||
```
|
```
|
||||||
|
|
||||||
#### Use as OCR-D processor
|
## Use as OCR-D processor
|
||||||
|
|
||||||
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) [processor](https://ocr-d.de/en/spec/cli),
|
See [`ocrd.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/ocrd.md).
|
||||||
formally described in [`ocrd-tool.json`](https://github.com/qurator-spk/eynollah/tree/main/src/eynollah/ocrd-tool.json).
|
|
||||||
|
|
||||||
In this case, the source image file group with (preferably) RGB images should be used as input like this:
|
|
||||||
|
|
||||||
ocrd-eynollah-segment -I OCR-D-IMG -O OCR-D-SEG -P models eynollah_layout_v0_6_0
|
|
||||||
|
|
||||||
If the input file group is PAGE-XML (from a previous OCR-D workflow step), Eynollah behaves as follows:
|
|
||||||
- existing regions are kept and ignored (i.e. in effect they might overlap segments from Eynollah results)
|
|
||||||
- existing annotation (and respective `AlternativeImage`s) are partially _ignored_:
|
|
||||||
- previous page frame detection (`cropped` images)
|
|
||||||
- previous derotation (`deskewed` images)
|
|
||||||
- previous thresholding (`binarized` images)
|
|
||||||
- if the page-level image nevertheless deviates from the original (`@imageFilename`)
|
|
||||||
(because some other preprocessing step was in effect like `denoised`), then
|
|
||||||
the output PAGE-XML will be based on that as new top-level (`@imageFilename`)
|
|
||||||
|
|
||||||
ocrd-eynollah-segment -I OCR-D-XYZ -O OCR-D-SEG -P models eynollah_layout_v0_6_0
|
|
||||||
|
|
||||||
In general, it makes more sense to add other workflow steps **after** Eynollah.
|
|
||||||
|
|
||||||
There is also an OCR-D processor for binarization:
|
|
||||||
|
|
||||||
ocrd-sbb-binarize -I OCR-D-IMG -O OCR-D-BIN -P models default-2021-03-09
|
|
||||||
|
|
||||||
#### Additional documentation
|
|
||||||
|
|
||||||
Additional documentation is available in the [docs](https://github.com/qurator-spk/eynollah/tree/main/docs) directory.
|
|
||||||
|
|
||||||
## How to cite
|
## How to cite
|
||||||
|
|
||||||
|
|
|
||||||
43
docs/docker.md
Normal file
43
docs/docker.md
Normal file
|
|
@ -0,0 +1,43 @@
|
||||||
|
## Inference with Docker
|
||||||
|
|
||||||
|
docker pull ghcr.io/qurator-spk/eynollah:latest
|
||||||
|
|
||||||
|
### 1. ocrd resource manager
|
||||||
|
(just once, to get the models and install them into a named volume for later re-use)
|
||||||
|
|
||||||
|
vol_models=ocrd-resources:/usr/local/share/ocrd-resources
|
||||||
|
docker run --rm -v $vol_models ocrd/eynollah ocrd resmgr download ocrd-eynollah-segment default
|
||||||
|
|
||||||
|
Now, each time you want to use Eynollah, pass the same resources volume again.
|
||||||
|
Also, bind-mount some data directory, e.g. current working directory $PWD (/data is default working directory in the container).
|
||||||
|
|
||||||
|
Either use standalone CLI (2) or OCR-D CLI (3):
|
||||||
|
|
||||||
|
### 2. standalone CLI
|
||||||
|
(follow self-help, cf. readme)
|
||||||
|
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data ocrd/eynollah eynollah binarization --help
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data ocrd/eynollah eynollah layout --help
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data ocrd/eynollah eynollah ocr --help
|
||||||
|
|
||||||
|
### 3. OCR-D CLI
|
||||||
|
(follow self-help, cf. readme and https://ocr-d.de/en/spec/cli)
|
||||||
|
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data ocrd/eynollah ocrd-eynollah-segment -h
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data ocrd/eynollah ocrd-sbb-binarize -h
|
||||||
|
|
||||||
|
Alternatively, just "log in" to the container once and use the commands there:
|
||||||
|
|
||||||
|
docker run --rm -v $vol_models -v $PWD:/data -it ocrd/eynollah bash
|
||||||
|
|
||||||
|
## Training with Docker
|
||||||
|
|
||||||
|
Build the Docker training image
|
||||||
|
|
||||||
|
cd train
|
||||||
|
docker build -t model-training .
|
||||||
|
|
||||||
|
Run the Docker training image
|
||||||
|
|
||||||
|
cd train
|
||||||
|
docker run --gpus all -v $PWD:/entry_point_dir model-training
|
||||||
18
docs/examples.md
Normal file
18
docs/examples.md
Normal file
|
|
@ -0,0 +1,18 @@
|
||||||
|
# Examples
|
||||||
|
|
||||||
|
Example outputs of various Eynollah models
|
||||||
|
|
||||||
|
# Binarisation
|
||||||
|
|
||||||
|
<img src="https://user-images.githubusercontent.com/952378/63592437-e433e400-c5b1-11e9-9c2d-889c6e93d748.jpg" width="45%"><img src="https://user-images.githubusercontent.com/952378/63592435-e433e400-c5b1-11e9-88e4-3e441b61fa67.jpg" width="45%">
|
||||||
|
<img src="https://user-images.githubusercontent.com/952378/63592440-e4cc7a80-c5b1-11e9-8964-2cd1b22c87be.jpg" width="45%"><img src="https://user-images.githubusercontent.com/952378/63592438-e4cc7a80-c5b1-11e9-86dc-a9e9f8555422.jpg" width="45%">
|
||||||
|
|
||||||
|
# Reading Order Detection
|
||||||
|
|
||||||
|
<img src="https://github.com/user-attachments/assets/42df2582-4579-415e-92f1-54858a02c830" alt="Input Image" width="45%">
|
||||||
|
<img src="https://github.com/user-attachments/assets/77fc819e-6302-4fc9-967c-ee11d10d863e" alt="Output Image" width="45%">
|
||||||
|
|
||||||
|
# OCR
|
||||||
|
|
||||||
|
<img src="https://github.com/user-attachments/assets/71054636-51c6-4117-b3cf-361c5cda3528" alt="Input Image" width="45%"><img src="https://github.com/user-attachments/assets/cfb3ce38-007a-4037-b547-21324a7d56dd" alt="Output Image" width="45%">
|
||||||
|
<img src="https://github.com/user-attachments/assets/343b2ed8-d818-4d4a-b301-f304cbbebfcd" alt="Input Image" width="45%"><img src="https://github.com/user-attachments/assets/accb5ba7-e37f-477e-84aa-92eafa0d136e" alt="Output Image" width="45%">
|
||||||
|
|
@ -18,7 +18,8 @@ Two Arabic/Persian terms form the name of the model suite: عين الله, whic
|
||||||
|
|
||||||
See the flowchart below for the different stages and how they interact:
|
See the flowchart below for the different stages and how they interact:
|
||||||
|
|
||||||
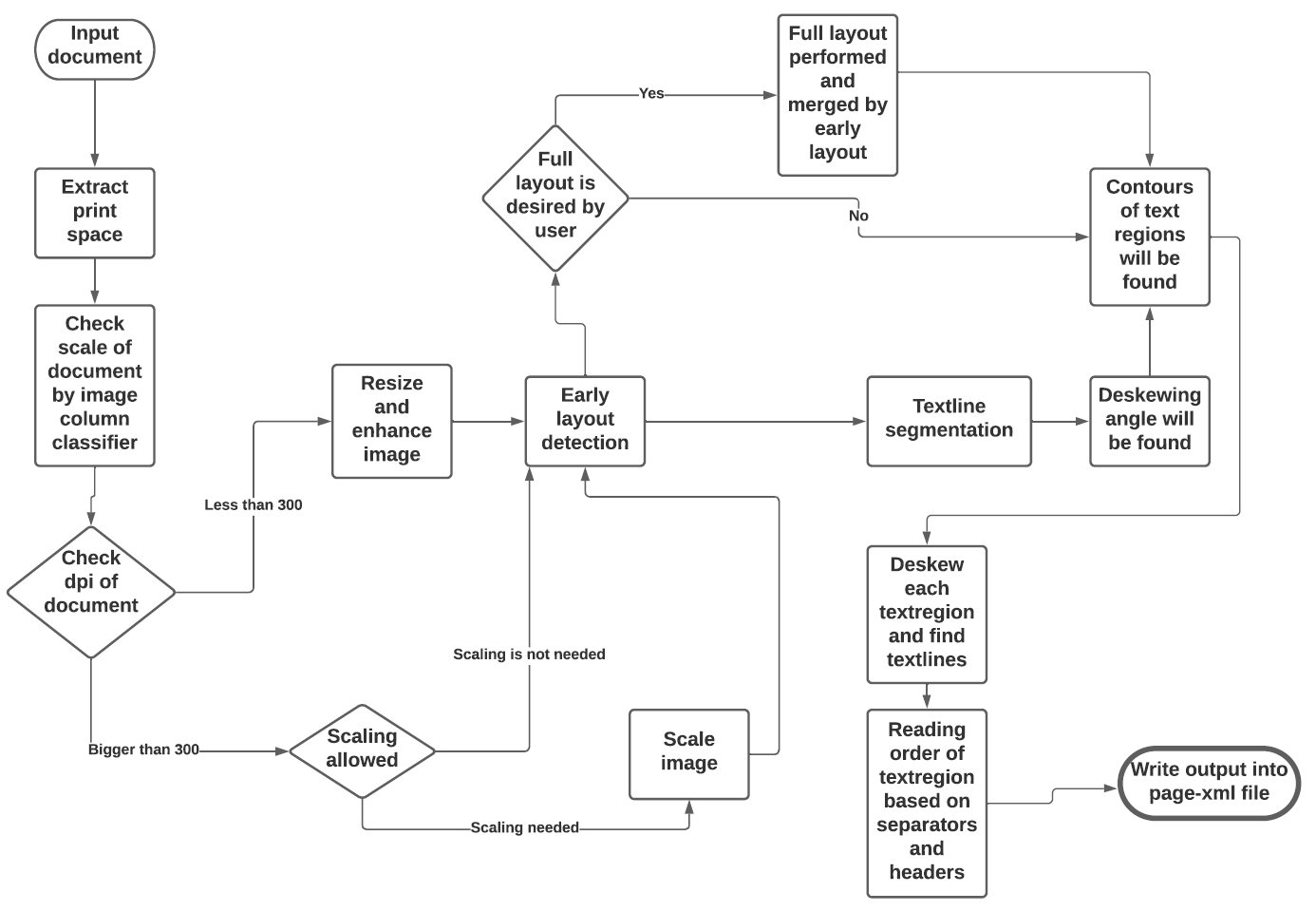
|
<img width="810" height="691" alt="eynollah_flowchart" src="https://github.com/user-attachments/assets/42dd55bc-7b85-4b46-9afe-15ff712607f0" />
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Models
|
## Models
|
||||||
|
|
@ -151,15 +152,75 @@ This model is used for the task of illustration detection only.
|
||||||
|
|
||||||
Model card: [Reading Order Detection]()
|
Model card: [Reading Order Detection]()
|
||||||
|
|
||||||
TODO
|
The model extracts the reading order of text regions from the layout by classifying pairwise relationships between them. A sorting algorithm then determines the overall reading sequence.
|
||||||
|
|
||||||
|
### OCR
|
||||||
|
|
||||||
|
We have trained three OCR models: two CNN-RNN–based models and one transformer-based TrOCR model. The CNN-RNN models are generally faster and provide better results in most cases, though their performance decreases with heavily degraded images. The TrOCR model, on the other hand, is computationally expensive and slower during inference, but it can possibly produce better results on strongly degraded images.
|
||||||
|
|
||||||
|
#### CNN-RNN model: model_eynollah_ocr_cnnrnn_20250805
|
||||||
|
|
||||||
|
This model is trained on data where most of the samples are in Fraktur german script.
|
||||||
|
|
||||||
|
| Dataset | Input | CER | WER |
|
||||||
|
|-----------------------|:-------|:-----------|:----------|
|
||||||
|
| OCR-D-GT-Archiveform | BIN | 0.02147 | 0.05685 |
|
||||||
|
| OCR-D-GT-Archiveform | RGB | 0.01636 | 0.06285 |
|
||||||
|
|
||||||
|
#### CNN-RNN model: model_eynollah_ocr_cnnrnn_20250904 (Default)
|
||||||
|
|
||||||
|
Compared to the model_eynollah_ocr_cnnrnn_20250805 model, this model is trained on a larger proportion of Antiqua data and achieves superior performance.
|
||||||
|
|
||||||
|
| Dataset | Input | CER | WER |
|
||||||
|
|-----------------------|:------------|:-----------|:----------|
|
||||||
|
| OCR-D-GT-Archiveform | BIN | 0.01635 | 0.05410 |
|
||||||
|
| OCR-D-GT-Archiveform | RGB | 0.01471 | 0.05813 |
|
||||||
|
| BLN600 | RGB | 0.04409 | 0.08879 |
|
||||||
|
| BLN600 | Enhanced | 0.03599 | 0.06244 |
|
||||||
|
|
||||||
|
|
||||||
|
#### Transformer OCR model: model_eynollah_ocr_trocr_20250919
|
||||||
|
|
||||||
|
This transformer OCR model is trained on the same data as model_eynollah_ocr_trocr_20250919.
|
||||||
|
|
||||||
|
| Dataset | Input | CER | WER |
|
||||||
|
|-----------------------|:------------|:-----------|:----------|
|
||||||
|
| OCR-D-GT-Archiveform | BIN | 0.01841 | 0.05589 |
|
||||||
|
| OCR-D-GT-Archiveform | RGB | 0.01552 | 0.06177 |
|
||||||
|
| BLN600 | RGB | 0.06347 | 0.13853 |
|
||||||
|
|
||||||
|
##### Qualitative evaluation of the models
|
||||||
|
|
||||||
|
| <img width="1600" src="https://github.com/user-attachments/assets/120fec0c-c370-46a6-b132-b0af800607cf"> | <img width="1000" src="https://github.com/user-attachments/assets/d84e6819-0a2a-4b3a-bb7d-ceac941babc4"> | <img width="1000" src="https://github.com/user-attachments/assets/bdd27cdb-bbec-4223-9a86-de7a27c6d018"> | <img width="1000" src="https://github.com/user-attachments/assets/1a507c75-75de-4da3-9545-af3746b9a207"> |
|
||||||
|
|:---:|:---:|:---:|:---:|
|
||||||
|
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
| <img width="2000" src="https://github.com/user-attachments/assets/9bc13d48-2a92-45fc-88db-c07ffadba067"> | <img width="1000" src="https://github.com/user-attachments/assets/2b294aeb-1362-4d6e-b70f-8aeffd94c5e7"> | <img width="1000" src="https://github.com/user-attachments/assets/9911317e-632e-4e6a-8839-1fb7e783da11"> | <img width="1000" src="https://github.com/user-attachments/assets/2c5626d9-0d23-49d3-80f5-a95f629c9c76"> |
|
||||||
|
|:---:|:---:|:---:|:---:|
|
||||||
|
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||||
|
|
||||||
|
|
||||||
|
| <img width="2000" src="https://github.com/user-attachments/assets/d54d8510-5c6a-4ab0-9ba7-f6ec4ad452c6"> | <img width="1000" src="https://github.com/user-attachments/assets/a418b25b-00dc-493a-b3a3-b325b9b0cb85"> | <img width="1000" src="https://github.com/user-attachments/assets/df6e2b9e-a821-4b4c-8868-0c765700c341"> | <img width="1000" src="https://github.com/user-attachments/assets/b90277f5-40f4-4c99-80a2-da400f7d3640"> |
|
||||||
|
|:---:|:---:|:---:|:---:|
|
||||||
|
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||||
|
|
||||||
|
|
||||||
|
| <img width="2000" src="https://github.com/user-attachments/assets/7ec49211-099f-4c21-9e60-47bfdf21f1b6"> | <img width="1000" src="https://github.com/user-attachments/assets/00ef9785-8885-41b3-bf6e-21eab743df71"> | <img width="1000" src="https://github.com/user-attachments/assets/13eb9f62-4d5a-46dc-befc-b02eb4f31fc1"> | <img width="1000" src="https://github.com/user-attachments/assets/a5c078d1-6d15-4d12-9040-526d7063d459"> |
|
||||||
|
|:---:|:---:|:---:|:---:|
|
||||||
|
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Heuristic methods
|
## Heuristic methods
|
||||||
|
|
||||||
Additionally, some heuristic methods are employed to further improve the model predictions:
|
Additionally, some heuristic methods are employed to further improve the model predictions:
|
||||||
|
|
||||||
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
||||||
* For text region detection, the image is scaled up to make it easier for the model to detect background space between text regions.
|
* Unlike the non-light version, where the image is scaled up to help the model better detect the background spaces between text regions, the light version uses down-scaled images. In this case, introducing an artificial class along the boundaries of text regions and text lines has helped to isolate and separate the text regions more effectively.
|
||||||
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
||||||
* Deskewing is applied on the text region level (due to regions having different degrees of skew) in order to improve the textline segmentation result.
|
* In the non-light version, deskewing is applied at the text-region level (since regions may have different degrees of skew) to improve text-line segmentation results. In contrast, the light version performs deskewing only at the page level to enhance margin detection and heuristic reading-order estimation.
|
||||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels.
|
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels (only in non-light version).
|
||||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline.
|
* Finally, using the derived coordinates, bounding boxes are determined for each textline (only in non-light version).
|
||||||
|
* As mentioned above, the reading order can be determined using a model; however, this approach is computationally expensive, time-consuming, and less accurate due to the limited amount of ground-truth data available for training. Therefore, our tool uses a heuristic reading-order detection method as the default. The heuristic approach relies on headers and separators to determine the reading order of text regions.
|
||||||
|
|
|
||||||
26
docs/ocrd.md
Normal file
26
docs/ocrd.md
Normal file
|
|
@ -0,0 +1,26 @@
|
||||||
|
## Use as OCR-D processor
|
||||||
|
|
||||||
|
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) [processor](https://ocr-d.de/en/spec/cli),
|
||||||
|
formally described in [`ocrd-tool.json`](https://github.com/qurator-spk/eynollah/tree/main/src/eynollah/ocrd-tool.json).
|
||||||
|
|
||||||
|
When using Eynollah in OCR-D, the source image file group with (preferably) RGB images should be used as input like this:
|
||||||
|
|
||||||
|
ocrd-eynollah-segment -I OCR-D-IMG -O OCR-D-SEG -P models eynollah_layout_v0_5_0
|
||||||
|
|
||||||
|
If the input file group is PAGE-XML (from a previous OCR-D workflow step), Eynollah behaves as follows:
|
||||||
|
- existing regions are kept and ignored (i.e. in effect they might overlap segments from Eynollah results)
|
||||||
|
- existing annotation (and respective `AlternativeImage`s) are partially _ignored_:
|
||||||
|
- previous page frame detection (`cropped` images)
|
||||||
|
- previous derotation (`deskewed` images)
|
||||||
|
- previous thresholding (`binarized` images)
|
||||||
|
- if the page-level image nevertheless deviates from the original (`@imageFilename`)
|
||||||
|
(because some other preprocessing step was in effect like `denoised`), then
|
||||||
|
the output PAGE-XML will be based on that as new top-level (`@imageFilename`)
|
||||||
|
|
||||||
|
ocrd-eynollah-segment -I OCR-D-XYZ -O OCR-D-SEG -P models eynollah_layout_v0_5_0
|
||||||
|
|
||||||
|
In general, it makes more sense to add other workflow steps **after** Eynollah.
|
||||||
|
|
||||||
|
There is also an OCR-D processor for binarization:
|
||||||
|
|
||||||
|
ocrd-sbb-binarize -I OCR-D-IMG -O OCR-D-BIN -P models default-2021-03-09
|
||||||
|
|
@ -1,3 +1,41 @@
|
||||||
|
# Prerequisistes
|
||||||
|
|
||||||
|
## 1. Install Eynollah with training dependencies
|
||||||
|
|
||||||
|
Clone the repository and install eynollah along with the dependencies necessary for training:
|
||||||
|
|
||||||
|
```sh
|
||||||
|
git clone https://github.com/qurator-spk/eynollah
|
||||||
|
cd eynollah
|
||||||
|
pip install '.[training]'
|
||||||
|
```
|
||||||
|
|
||||||
|
## 2. Pretrained encoder
|
||||||
|
|
||||||
|
Download our pretrained weights and add them to a `train/pretrained_model` folder:
|
||||||
|
|
||||||
|
```sh
|
||||||
|
cd train
|
||||||
|
wget -O pretrained_model.tar.gz https://zenodo.org/records/17243320/files/pretrained_model_v0_5_1.tar.gz?download=1
|
||||||
|
tar xf pretrained_model.tar.gz
|
||||||
|
```
|
||||||
|
|
||||||
|
## 3. Example data
|
||||||
|
|
||||||
|
### Binarization
|
||||||
|
A small sample of training data for binarization experiment can be found on [Zenodo](https://zenodo.org/records/17243320/files/training_data_sample_binarization_v0_5_1.tar.gz?download=1),
|
||||||
|
which contains `images` and `labels` folders.
|
||||||
|
|
||||||
|
## 4. Helpful tools
|
||||||
|
|
||||||
|
* [`pagexml2img`](https://github.com/qurator-spk/page2img)
|
||||||
|
> Tool to extract 2-D or 3-D RGB images from PAGE-XML data. In the former case, the output will be 1 2-D image array which each class has filled with a pixel value. In the case of a 3-D RGB image,
|
||||||
|
each class will be defined with a RGB value and beside images, a text file of classes will also be produced.
|
||||||
|
* [`cocoSegmentationToPng`](https://github.com/nightrome/cocostuffapi/blob/17acf33aef3c6cc2d6aca46dcf084266c2778cf0/PythonAPI/pycocotools/cocostuffhelper.py#L130)
|
||||||
|
> Convert COCO GT or results for a single image to a segmentation map and write it to disk.
|
||||||
|
* [`ocrd-segment-extract-pages`](https://github.com/OCR-D/ocrd_segment/blob/master/ocrd_segment/extract_pages.py)
|
||||||
|
> Extract region classes and their colours in mask (pseg) images. Allows the color map as free dict parameter, and comes with a default that mimics PageViewer's coloring for quick debugging; it also warns when regions do overlap.
|
||||||
|
|
||||||
# Training documentation
|
# Training documentation
|
||||||
|
|
||||||
This document aims to assist users in preparing training datasets, training models, and
|
This document aims to assist users in preparing training datasets, training models, and
|
||||||
|
|
|
||||||
|
|
@ -11,7 +11,12 @@ description = "Document Layout Analysis"
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
license.file = "LICENSE"
|
license.file = "LICENSE"
|
||||||
requires-python = ">=3.8"
|
requires-python = ">=3.8"
|
||||||
keywords = ["document layout analysis", "image segmentation"]
|
keywords = [
|
||||||
|
"document layout analysis",
|
||||||
|
"image segmentation",
|
||||||
|
"binarization",
|
||||||
|
"optical character recognition"
|
||||||
|
]
|
||||||
|
|
||||||
dynamic = [
|
dynamic = [
|
||||||
"dependencies",
|
"dependencies",
|
||||||
|
|
@ -25,6 +30,10 @@ classifiers = [
|
||||||
"Intended Audience :: Science/Research",
|
"Intended Audience :: Science/Research",
|
||||||
"License :: OSI Approved :: Apache Software License",
|
"License :: OSI Approved :: Apache Software License",
|
||||||
"Programming Language :: Python :: 3",
|
"Programming Language :: Python :: 3",
|
||||||
|
"Programming Language :: Python :: 3.8",
|
||||||
|
"Programming Language :: Python :: 3.9",
|
||||||
|
"Programming Language :: Python :: 3.10",
|
||||||
|
"Programming Language :: Python :: 3.11",
|
||||||
"Programming Language :: Python :: 3 :: Only",
|
"Programming Language :: Python :: 3 :: Only",
|
||||||
"Topic :: Scientific/Engineering :: Image Processing",
|
"Topic :: Scientific/Engineering :: Image Processing",
|
||||||
]
|
]
|
||||||
|
|
|
||||||
|
|
@ -1,59 +0,0 @@
|
||||||
# Training eynollah
|
|
||||||
|
|
||||||
This README explains the technical details of how to set up and run training, for detailed information on parameterization, see [`docs/train.md`](../docs/train.md)
|
|
||||||
|
|
||||||
## Introduction
|
|
||||||
|
|
||||||
This folder contains the source code for training an encoder model for document image segmentation.
|
|
||||||
|
|
||||||
## Installation
|
|
||||||
|
|
||||||
Clone the repository and install eynollah along with the dependencies necessary for training:
|
|
||||||
|
|
||||||
```sh
|
|
||||||
git clone https://github.com/qurator-spk/eynollah
|
|
||||||
cd eynollah
|
|
||||||
pip install '.[training]'
|
|
||||||
```
|
|
||||||
|
|
||||||
### Pretrained encoder
|
|
||||||
|
|
||||||
Download our pretrained weights and add them to a `train/pretrained_model` folder:
|
|
||||||
|
|
||||||
```sh
|
|
||||||
cd train
|
|
||||||
wget -O pretrained_model.tar.gz "https://zenodo.org/records/17295988/files/pretrained_model_v0_6_0.tar.gz?download=1"
|
|
||||||
tar xf pretrained_model.tar.gz
|
|
||||||
```
|
|
||||||
|
|
||||||
### Binarization training data
|
|
||||||
|
|
||||||
A small sample of training data for binarization experiment can be found [on
|
|
||||||
zenodo](https://zenodo.org/records/17295988/files/training_data_sample_binarization_v0_6_0.tar.gz?download=1),
|
|
||||||
which contains `images` and `labels` folders.
|
|
||||||
|
|
||||||
### Helpful tools
|
|
||||||
|
|
||||||
* [`pagexml2img`](https://github.com/qurator-spk/page2img)
|
|
||||||
> Tool to extract 2-D or 3-D RGB images from PAGE-XML data. In the former case, the output will be 1 2-D image array which each class has filled with a pixel value. In the case of a 3-D RGB image,
|
|
||||||
each class will be defined with a RGB value and beside images, a text file of classes will also be produced.
|
|
||||||
* [`cocoSegmentationToPng`](https://github.com/nightrome/cocostuffapi/blob/17acf33aef3c6cc2d6aca46dcf084266c2778cf0/PythonAPI/pycocotools/cocostuffhelper.py#L130)
|
|
||||||
> Convert COCO GT or results for a single image to a segmentation map and write it to disk.
|
|
||||||
* [`ocrd-segment-extract-pages`](https://github.com/OCR-D/ocrd_segment/blob/master/ocrd_segment/extract_pages.py)
|
|
||||||
> Extract region classes and their colours in mask (pseg) images. Allows the color map as free dict parameter, and comes with a default that mimics PageViewer's coloring for quick debugging; it also warns when regions do overlap.
|
|
||||||
|
|
||||||
### Train using Docker
|
|
||||||
|
|
||||||
Build the Docker image:
|
|
||||||
|
|
||||||
```bash
|
|
||||||
cd train
|
|
||||||
docker build -t model-training .
|
|
||||||
```
|
|
||||||
|
|
||||||
Run Docker image
|
|
||||||
|
|
||||||
```bash
|
|
||||||
cd train
|
|
||||||
docker run --gpus all -v $PWD:/entry_point_dir model-training
|
|
||||||
```
|
|
||||||
Loading…
Add table
Add a link
Reference in a new issue