mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-08-03 01:12:46 +02:00
Merge remote-tracking branch 'origin/updating_docs' into docs_and_minor_fixes
This commit is contained in:
commit
8822da17cf
2 changed files with 129 additions and 27 deletions
|
|
@ -18,7 +18,8 @@ Two Arabic/Persian terms form the name of the model suite: عين الله, whic
|
|||
|
||||
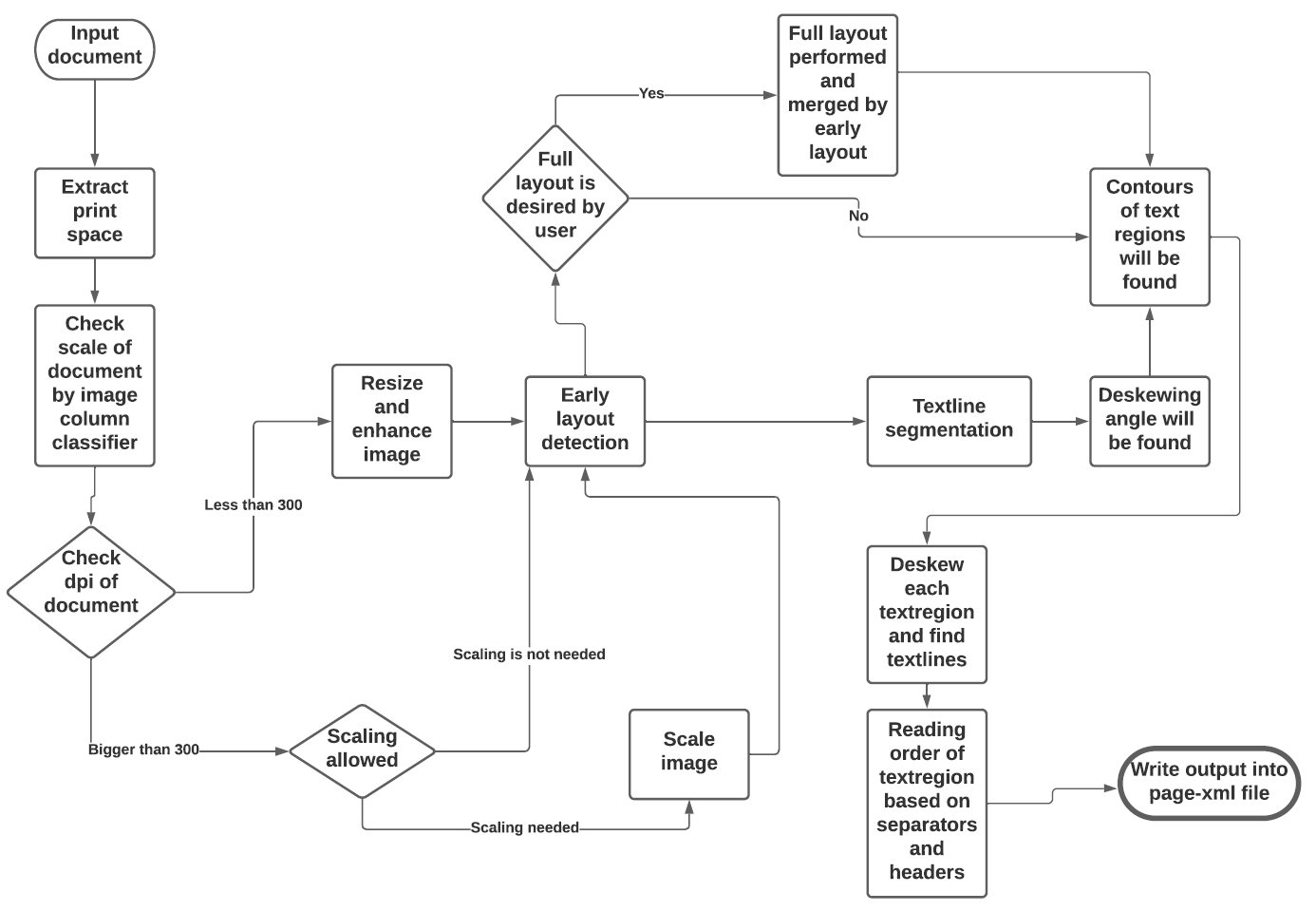
See the flowchart below for the different stages and how they interact:
|
||||
|
||||
|
||||
<img width="810" height="691" alt="eynollah_flowchart" src="https://github.com/user-attachments/assets/42dd55bc-7b85-4b46-9afe-15ff712607f0" />
|
||||
|
||||
|
||||
|
||||
## Models
|
||||
|
|
@ -151,15 +152,75 @@ This model is used for the task of illustration detection only.
|
|||
|
||||
Model card: [Reading Order Detection]()
|
||||
|
||||
TODO
|
||||
The model extracts the reading order of text regions from the layout by classifying pairwise relationships between them. A sorting algorithm then determines the overall reading sequence.
|
||||
|
||||
### OCR
|
||||
|
||||
We have trained three OCR models: two CNN-RNN–based models and one transformer-based TrOCR model. The CNN-RNN models are generally faster and provide better results in most cases, though their performance decreases with heavily degraded images. The TrOCR model, on the other hand, is computationally expensive and slower during inference, but it can possibly produce better results on strongly degraded images.
|
||||
|
||||
#### CNN-RNN model: model_eynollah_ocr_cnnrnn_20250805
|
||||
|
||||
This model is trained on data where most of the samples are in Fraktur german script.
|
||||
|
||||
| Dataset | Input | CER | WER |
|
||||
|-----------------------|:-------|:-----------|:----------|
|
||||
| OCR-D-GT-Archiveform | BIN | 0.02147 | 0.05685 |
|
||||
| OCR-D-GT-Archiveform | RGB | 0.01636 | 0.06285 |
|
||||
|
||||
#### CNN-RNN model: model_eynollah_ocr_cnnrnn_20250904 (Default)
|
||||
|
||||
Compared to the model_eynollah_ocr_cnnrnn_20250805 model, this model is trained on a larger proportion of Antiqua data and achieves superior performance.
|
||||
|
||||
| Dataset | Input | CER | WER |
|
||||
|-----------------------|:------------|:-----------|:----------|
|
||||
| OCR-D-GT-Archiveform | BIN | 0.01635 | 0.05410 |
|
||||
| OCR-D-GT-Archiveform | RGB | 0.01471 | 0.05813 |
|
||||
| BLN600 | RGB | 0.04409 | 0.08879 |
|
||||
| BLN600 | Enhanced | 0.03599 | 0.06244 |
|
||||
|
||||
|
||||
#### Transformer OCR model: model_eynollah_ocr_trocr_20250919
|
||||
|
||||
This transformer OCR model is trained on the same data as model_eynollah_ocr_trocr_20250919.
|
||||
|
||||
| Dataset | Input | CER | WER |
|
||||
|-----------------------|:------------|:-----------|:----------|
|
||||
| OCR-D-GT-Archiveform | BIN | 0.01841 | 0.05589 |
|
||||
| OCR-D-GT-Archiveform | RGB | 0.01552 | 0.06177 |
|
||||
| BLN600 | RGB | 0.06347 | 0.13853 |
|
||||
|
||||
##### Qualitative evaluation of the models
|
||||
|
||||
| <img width="1600" src="https://github.com/user-attachments/assets/120fec0c-c370-46a6-b132-b0af800607cf"> | <img width="1000" src="https://github.com/user-attachments/assets/d84e6819-0a2a-4b3a-bb7d-ceac941babc4"> | <img width="1000" src="https://github.com/user-attachments/assets/bdd27cdb-bbec-4223-9a86-de7a27c6d018"> | <img width="1000" src="https://github.com/user-attachments/assets/1a507c75-75de-4da3-9545-af3746b9a207"> |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||
|
||||
|
||||
|
||||
| <img width="2000" src="https://github.com/user-attachments/assets/9bc13d48-2a92-45fc-88db-c07ffadba067"> | <img width="1000" src="https://github.com/user-attachments/assets/2b294aeb-1362-4d6e-b70f-8aeffd94c5e7"> | <img width="1000" src="https://github.com/user-attachments/assets/9911317e-632e-4e6a-8839-1fb7e783da11"> | <img width="1000" src="https://github.com/user-attachments/assets/2c5626d9-0d23-49d3-80f5-a95f629c9c76"> |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||
|
||||
|
||||
| <img width="2000" src="https://github.com/user-attachments/assets/d54d8510-5c6a-4ab0-9ba7-f6ec4ad452c6"> | <img width="1000" src="https://github.com/user-attachments/assets/a418b25b-00dc-493a-b3a3-b325b9b0cb85"> | <img width="1000" src="https://github.com/user-attachments/assets/df6e2b9e-a821-4b4c-8868-0c765700c341"> | <img width="1000" src="https://github.com/user-attachments/assets/b90277f5-40f4-4c99-80a2-da400f7d3640"> |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||
|
||||
|
||||
| <img width="2000" src="https://github.com/user-attachments/assets/7ec49211-099f-4c21-9e60-47bfdf21f1b6"> | <img width="1000" src="https://github.com/user-attachments/assets/00ef9785-8885-41b3-bf6e-21eab743df71"> | <img width="1000" src="https://github.com/user-attachments/assets/13eb9f62-4d5a-46dc-befc-b02eb4f31fc1"> | <img width="1000" src="https://github.com/user-attachments/assets/a5c078d1-6d15-4d12-9040-526d7063d459"> |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image | cnnrnn_20250805 | cnnrnn_20250904 | trocr_20250919 |
|
||||
|
||||
|
||||
|
||||
## Heuristic methods
|
||||
|
||||
Additionally, some heuristic methods are employed to further improve the model predictions:
|
||||
|
||||
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
||||
* For text region detection, the image is scaled up to make it easier for the model to detect background space between text regions.
|
||||
* Unlike the non-light version, where the image is scaled up to help the model better detect the background spaces between text regions, the light version uses down-scaled images. In this case, introducing an artificial class along the boundaries of text regions and text lines has helped to isolate and separate the text regions more effectively.
|
||||
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
||||
* Deskewing is applied on the text region level (due to regions having different degrees of skew) in order to improve the textline segmentation result.
|
||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels.
|
||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline.
|
||||
* In the non-light version, deskewing is applied at the text-region level (since regions may have different degrees of skew) to improve text-line segmentation results. In contrast, the light version performs deskewing only at the page level to enhance margin detection and heuristic reading-order estimation.
|
||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels (only in non-light version).
|
||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline (only in non-light version).
|
||||
* As mentioned above, the reading order can be determined using a model; however, this approach is computationally expensive, time-consuming, and less accurate due to the limited amount of ground-truth data available for training. Therefore, our tool uses a heuristic reading-order detection method as the default. The heuristic approach relies on headers and separators to determine the reading order of text regions.
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue