mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-07-14 07:39:15 +02:00
updating readme
This commit is contained in:
parent
94c3b0fc28
commit
e564451861
1 changed files with 119 additions and 69 deletions
188
README.md
188
README.md
|
|
@ -1,61 +1,8 @@
|
|||
# Eynollah
|
||||
> Document Layout Analysis
|
||||
> Perform document layout analysis (segmentation) from image data and return the results as [PAGE-XML](https://github.com/PRImA-Research-Lab/PAGE-XML).
|
||||
|
||||

|
||||
|
||||
## Introduction
|
||||
This tool performs document layout analysis (segmentation) from image data and returns the results as [PAGE-XML](https://github.com/PRImA-Research-Lab/PAGE-XML).
|
||||
|
||||
It can currently detect the following layout classes/elements:
|
||||
* [Border](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_BorderType.html)
|
||||
* [Textregion](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextRegionType.html)
|
||||
* [Textline](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextLineType.html)
|
||||
* [Image](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_ImageRegionType.html)
|
||||
* [Separator](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_SeparatorRegionType.html)
|
||||
* [Marginalia](https://ocr-d.de/en/gt-guidelines/trans/lyMarginalie.html)
|
||||
* [Initial (Drop Capital)](https://ocr-d.de/en/gt-guidelines/trans/lyInitiale.html)
|
||||
|
||||
In addition, the tool can be used to detect the _[ReadingOrder](https://ocr-d.de/en/gt-guidelines/trans/lyLeserichtung.html)_ of regions. The final goal is to feed the output to an OCR model.
|
||||
|
||||
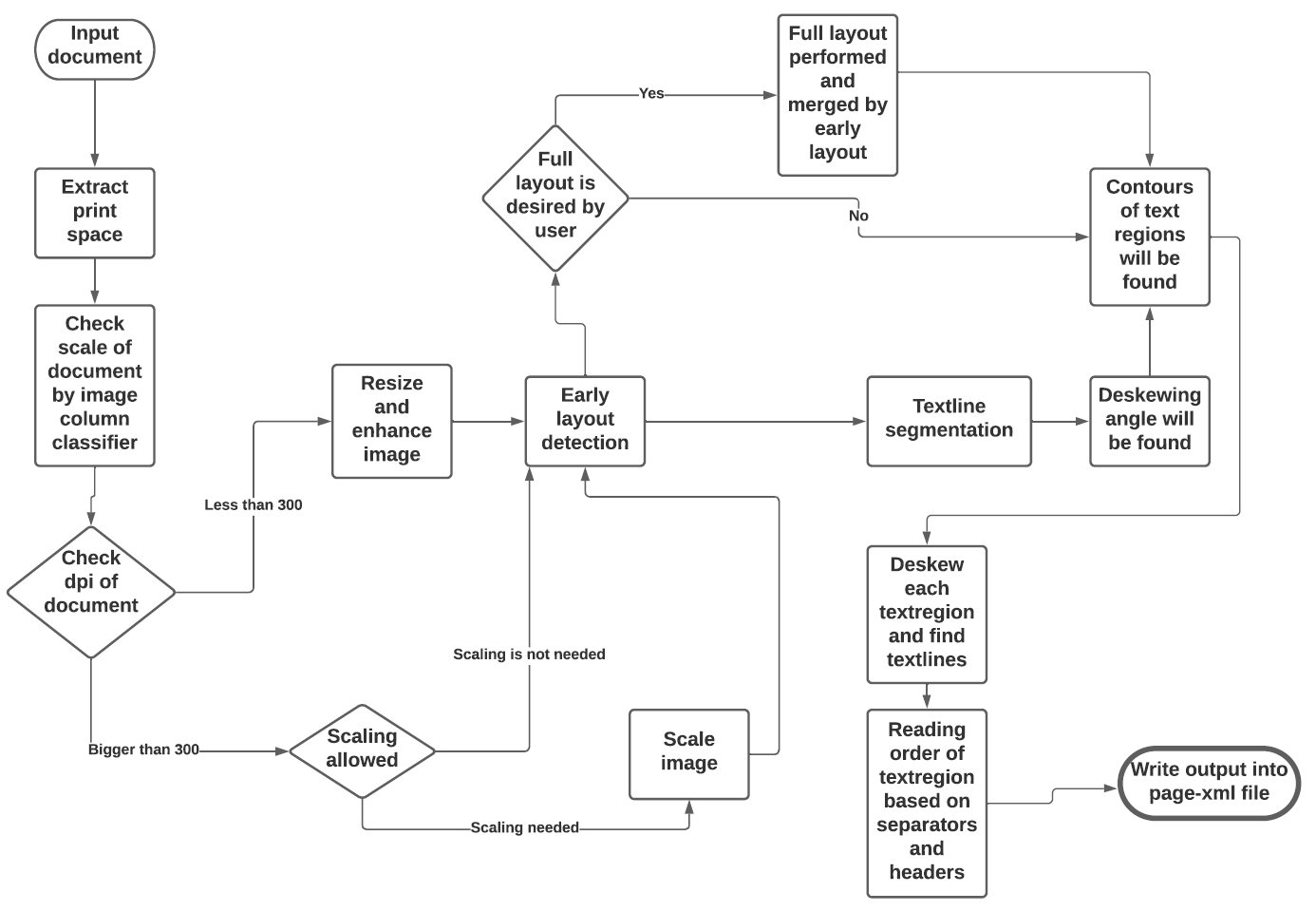
The tool uses a combination of various models and heuristics (see flowchart below for the different stages and how they interact):
|
||||
* [Border detection](https://github.com/qurator-spk/eynollah#border-detection)
|
||||
* [Layout detection](https://github.com/qurator-spk/eynollah#layout-detection)
|
||||
* [Textline detection](https://github.com/qurator-spk/eynollah#textline-detection)
|
||||
* [Image enhancement](https://github.com/qurator-spk/eynollah#Image_enhancement)
|
||||
* [Scale classification](https://github.com/qurator-spk/eynollah#Scale_classification)
|
||||
* [Heuristic methods](https://https://github.com/qurator-spk/eynollah#heuristic-methods)
|
||||
|
||||
The first three stages are based on [pixel-wise segmentation](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
||||
|
||||
|
||||
|
||||
## Border detection
|
||||
For the purpose of text recognition (OCR) and in order to avoid noise being introduced from texts outside the printspace, one first needs to detect the border of the printed frame. This is done by a binary pixel-wise-segmentation model trained on a dataset of 2,000 documents where about 1,200 of them come from the [dhSegment](https://github.com/dhlab-epfl/dhSegment/) project (you can download the dataset from [here](https://github.com/dhlab-epfl/dhSegment/releases/download/v0.2/pages.zip)) and the remainder having been annotated in SBB. For border detection, the model needs to be fed with the whole image at once rather than separated in patches.
|
||||
|
||||
## Layout detection
|
||||
As a next step, text regions need to be identified by means of layout detection. Again a pixel-wise segmentation model was trained on 131 labeled images from the SBB digital collections, including some data augmentation. Since the target of this tool are historical documents, we consider as main region types text regions, separators, images, tables and background - each with their own subclasses, e.g. in the case of text regions, subclasses like header/heading, drop capital, main body text etc. While it would be desirable to detect and classify each of these classes in a granular way, there are also limitations due to having a suitably large and balanced training set. Accordingly, the current version of this tool is focussed on the main region types background, text region, image and separator.
|
||||
|
||||
## Textline detection
|
||||
In a subsequent step, binary pixel-wise segmentation is used again to classify pixels in a document that constitute textlines. For textline segmentation, a model was initially trained on documents with only one column/block of text and some augmentation with regard to scaling. By fine-tuning the parameters also for multi-column documents, additional training data was produced that resulted in a much more robust textline detection model.
|
||||
|
||||
## Image enhancement
|
||||
This is an image to image model which input was low quality of an image and label was actually the original image. For this one we did not have any GT, so we decreased the quality of documents in SBB and then feed them into model.
|
||||
|
||||
## Scale classification
|
||||
This is simply an image classifier which classifies images based on their scales or better to say based on their number of columns.
|
||||
|
||||
## Heuristic methods
|
||||
Some heuristic methods are also employed to further improve the model predictions:
|
||||
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
||||
* For text region detection, the image is scaled up to make it easier for the model to detect background space between text regions.
|
||||
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
||||
* Deskewing is applied on the text region level (due to regions having different degrees of skew) in order to improve the textline segmentation result.
|
||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels.
|
||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline.
|
||||
|
||||
## Light version
|
||||
layout detection is implemented in lower scale and with only one model.
|
||||
|
||||
## Installation
|
||||
`pip install .` or
|
||||
|
||||
|
|
@ -69,13 +16,17 @@ Alternatively, you can also use `make` with these targets:
|
|||
|
||||
### Models
|
||||
|
||||
In order to run this tool you also need trained models. You can download our pretrained models from [qurator-data.de](https://qurator-data.de/eynollah/).
|
||||
In order to run this tool you need trained models. You can download our pretrained models from [qurator-data.de](https://qurator-data.de/eynollah/).
|
||||
|
||||
Alternatively, running `make models` will download and extract models to `$(PWD)/models_eynollah`.
|
||||
|
||||
### Training
|
||||
|
||||
In case you want to train your own model to use with Eynollah, have a look at [sbb_pixelwise_segmentation](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
||||
|
||||
## Usage
|
||||
|
||||
The basic command-line interface can be called like this:
|
||||
The command-line interface can be called like this:
|
||||
|
||||
```sh
|
||||
eynollah \
|
||||
|
|
@ -99,25 +50,88 @@ eynollah \
|
|||
|
||||
```
|
||||
|
||||
The tool does accept and works better on original images (RGB format) than binarized images.
|
||||
The tool performs better with RGB images than greyscale/binarized images.
|
||||
|
||||
### `--full-layout` vs `--no-full-layout`
|
||||
## Documentation
|
||||
|
||||
<details>
|
||||
<summary>click to expand/collapse</summary>
|
||||
|
||||
Here are the difference in elements detected depending on the `--full-layout`/`--no-full-layout` command line flags:
|
||||
### Region types
|
||||
|
||||
| | `--full-layout` | `--no-full-layout` |
|
||||
| --- | --- | --- |
|
||||
| reading order | x | x |
|
||||
| header regions | x | - |
|
||||
| text regions | x | x |
|
||||
| text regions / text line | x | x |
|
||||
| drop-capitals | x | - |
|
||||
| marginals | x | x |
|
||||
| marginals / text line | x | x |
|
||||
| image region | x | x |
|
||||
<details>
|
||||
<summary>click to expand/collapse</summary><br/>
|
||||
|
||||
Eynollah can currently be used to detect the following region types/elements:
|
||||
* [Border](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_BorderType.html)
|
||||
* [Textregion](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextRegionType.html)
|
||||
* [Textline](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_TextLineType.html)
|
||||
* [Image](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_ImageRegionType.html)
|
||||
* [Separator](https://ocr-d.de/en/gt-guidelines/pagexml/pagecontent_xsd_Complex_Type_pc_SeparatorRegionType.html)
|
||||
* [Marginalia](https://ocr-d.de/en/gt-guidelines/trans/lyMarginalie.html)
|
||||
* [Initial (Drop Capital)](https://ocr-d.de/en/gt-guidelines/trans/lyInitiale.html)
|
||||
|
||||
In addition, the tool can detect the [ReadingOrder](https://ocr-d.de/en/gt-guidelines/trans/lyLeserichtung.html) of regions. The final goal is to feed the output to an OCR model.
|
||||
|
||||
</details>
|
||||
|
||||
### Method description
|
||||
|
||||
<details>
|
||||
<summary>click to expand/collapse</summary><br/>
|
||||
|
||||
Eynollah uses a combination of various models and heuristics (see flowchart below for the different stages and how they interact):
|
||||
* [Border detection](https://github.com/qurator-spk/eynollah#border-detection)
|
||||
* [Layout detection](https://github.com/qurator-spk/eynollah#layout-detection)
|
||||
* [Textline detection](https://github.com/qurator-spk/eynollah#textline-detection)
|
||||
* [Image enhancement](https://github.com/qurator-spk/eynollah#Image_enhancement)
|
||||
* [Scale classification](https://github.com/qurator-spk/eynollah#Scale_classification)
|
||||
* [Heuristic methods](https://https://github.com/qurator-spk/eynollah#heuristic-methods)
|
||||
|
||||
The first three stages are based on [pixel-wise segmentation](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
||||
|
||||

|
||||
|
||||
#### Border detection
|
||||
For the purpose of text recognition (OCR) and in order to avoid noise being introduced from texts outside the printspace, one first needs to detect the border of the printed frame. This is done by a binary pixel-wise-segmentation model trained on a dataset of 2,000 documents where about 1,200 of them come from the [dhSegment](https://github.com/dhlab-epfl/dhSegment/) project (you can download the dataset from [here](https://github.com/dhlab-epfl/dhSegment/releases/download/v0.2/pages.zip)) and the remainder having been annotated in SBB. For border detection, the model needs to be fed with the whole image at once rather than separated in patches.
|
||||
|
||||
### Layout detection
|
||||
As a next step, text regions need to be identified by means of layout detection. Again a pixel-wise segmentation model was trained on 131 labeled images from the SBB digital collections, including some data augmentation. Since the target of this tool are historical documents, we consider as main region types text regions, separators, images, tables and background - each with their own subclasses, e.g. in the case of text regions, subclasses like header/heading, drop capital, main body text etc. While it would be desirable to detect and classify each of these classes in a granular way, there are also limitations due to having a suitably large and balanced training set. Accordingly, the current version of this tool is focussed on the main region types background, text region, image and separator.
|
||||
|
||||
#### Textline detection
|
||||
In a subsequent step, binary pixel-wise segmentation is used again to classify pixels in a document that constitute textlines. For textline segmentation, a model was initially trained on documents with only one column/block of text and some augmentation with regard to scaling. By fine-tuning the parameters also for multi-column documents, additional training data was produced that resulted in a much more robust textline detection model.
|
||||
|
||||
#### Image enhancement
|
||||
This is an image to image model which input was low quality of an image and label was actually the original image. For this one we did not have any GT, so we decreased the quality of documents in SBB and then feed them into model.
|
||||
|
||||
#### Scale classification
|
||||
This is simply an image classifier which classifies images based on their scales or better to say based on their number of columns.
|
||||
|
||||
### Heuristic methods
|
||||
Some heuristic methods are also employed to further improve the model predictions:
|
||||
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
||||
* For text region detection, the image is scaled up to make it easier for the model to detect background space between text regions.
|
||||
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
||||
* Deskewing is applied on the text region level (due to regions having different degrees of skew) in order to improve the textline segmentation result.
|
||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels.
|
||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline.
|
||||
|
||||
</details>
|
||||
|
||||
### Model description
|
||||
|
||||
<details>
|
||||
<summary>click to expand/collapse</summary><br/>
|
||||
|
||||
TODO
|
||||
|
||||
</details>
|
||||
|
||||
### How to use
|
||||
|
||||
<details>
|
||||
<summary>click to expand/collapse</summary><br/>
|
||||
|
||||
First, this model makes use of up to 9 trained models which are responsible for different operations like size detection, column classification, image enhancement, page extraction, main layout detection, full layout detection and textline detection.That does not mean that all 9 models are always required for every document. Based on the document characteristics and parameters specified, different scenarios can be applied.
|
||||
|
||||
* If none of the parameters is set to `true`, the tool will perform a layout detection of main regions (background, text, images, separators and marginals). An advantage of this tool is that it tries to extract main text regions separately as much as possible.
|
||||
|
|
@ -133,3 +147,39 @@ First, this model makes use of up to 9 trained models which are responsible for
|
|||
* To crop and save image regions inside the document, set the parameter `-si` (**s**ave **i**mages) to true and provide a directory path to store the extracted images.
|
||||
|
||||
* This tool is actively being developed. If problems occur, or the performance does not meet your expectations, we welcome your feedback via [issues](https://github.com/qurator-spk/eynollah/issues).
|
||||
|
||||
#### `--full-layout` vs `--no-full-layout`
|
||||
|
||||
Here are the difference in elements detected depending on the `--full-layout`/`--no-full-layout` command line flags:
|
||||
|
||||
| | `--full-layout` | `--no-full-layout` |
|
||||
| --- | --- | --- |
|
||||
| reading order | x | x |
|
||||
| header regions | x | - |
|
||||
| text regions | x | x |
|
||||
| text regions / text line | x | x |
|
||||
| drop-capitals | x | - |
|
||||
| marginals | x | x |
|
||||
| marginals / text line | x | x |
|
||||
| image region | x | x |
|
||||
|
||||
#### Use as OCR-D processor
|
||||
|
||||
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) processor. In this case, the source image file group with (preferably) RGB images should be used as input like this:
|
||||
|
||||
`ocrd-eynollah-segment -I OCR-D-IMG -O SEG-LINE -P models`
|
||||
|
||||
In fact, the image referenced by `@imageFilename` in PAGE-XML is passed on directly to Eynollah as a processor, so that e.g. calling
|
||||
|
||||
`ocrd-eynollah-segment -I OCR-D-IMG-BIN -O SEG-LINE -P models`
|
||||
|
||||
would still use the original (RGB) image despite any binarization that may have occured in previous OCR-D processing steps
|
||||
|
||||
#### Eynollah "light"
|
||||
|
||||
TODO
|
||||
|
||||
</details>
|
||||
|
||||
</details>
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue