mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-08-03 01:12:46 +02:00
consolidate usage documentation
This commit is contained in:
parent
e9fa691308
commit
3a55b6ce91
2 changed files with 99 additions and 0 deletions
|
|
@ -16,8 +16,10 @@ Two Arabic/Persian terms form the name of the model suite: عين الله, whic
|
|||
"eynollah"; it translates into English as "God's Eye" -- it sees (nearly) everything on the document image.
|
||||
|
||||
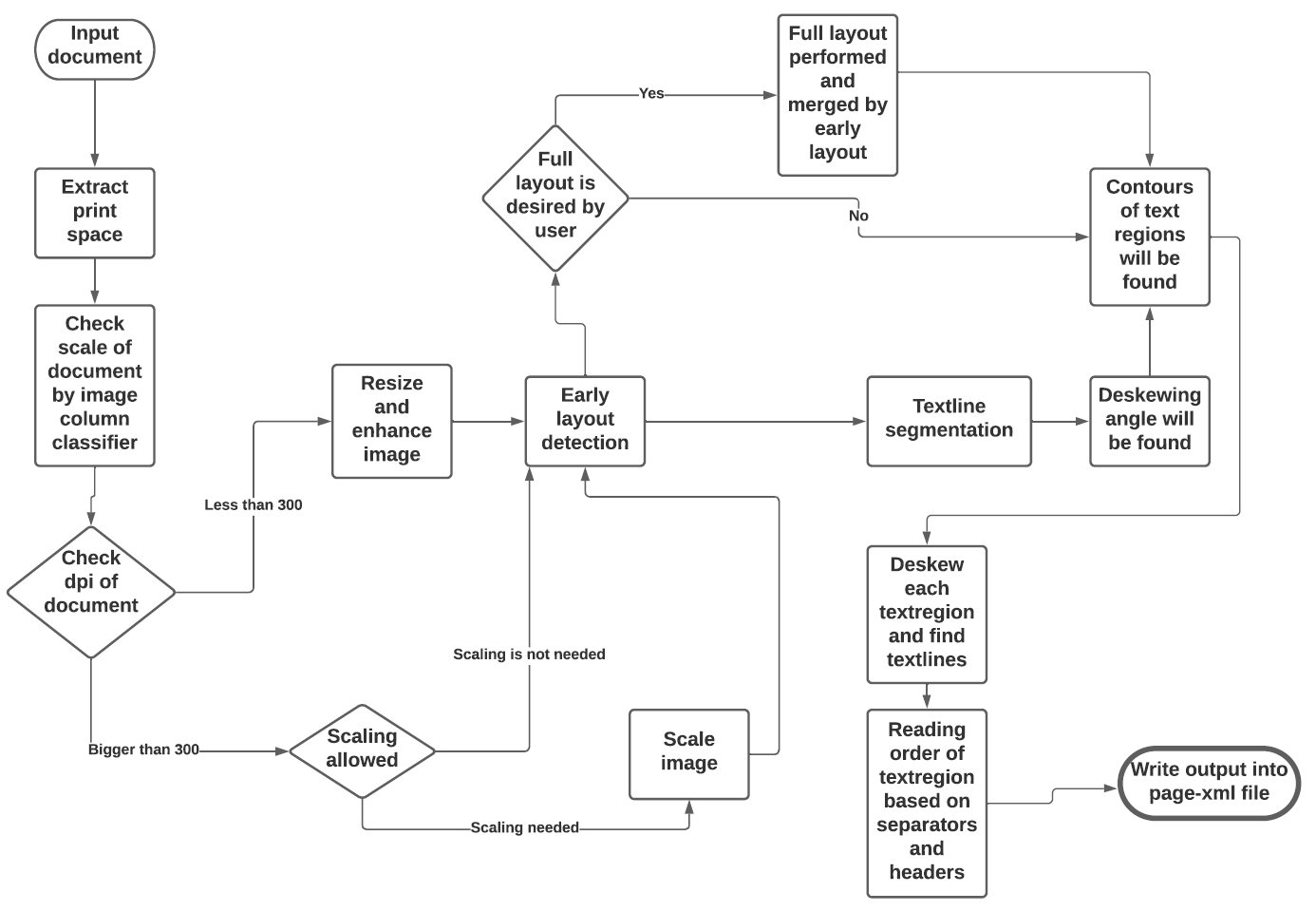
See the flowchart below for the different stages and how they interact:
|
||||
|
||||
|
||||
|
||||
|
||||
## Models
|
||||
|
||||
### Image enhancement
|
||||
|
|
|
|||
97
docs/usage.md
Normal file
97
docs/usage.md
Normal file
|
|
@ -0,0 +1,97 @@
|
|||
# Usage documentation
|
||||
The command-line interface can be called like this:
|
||||
|
||||
```sh
|
||||
eynollah \
|
||||
-i <single image file> | -di <directory containing image files> \
|
||||
-o <output directory> \
|
||||
-m <directory containing model files> \
|
||||
[OPTIONS]
|
||||
```
|
||||
|
||||
The following options can be used to further configure the processing:
|
||||
|
||||
| option | description |
|
||||
|-------------------|:-------------------------------------------------------------------------------|
|
||||
| `-fl` | full layout analysis including all steps and segmentation classes |
|
||||
| `-light` | lighter and faster but simpler method for main region detection and deskewing |
|
||||
| `-tab` | apply table detection |
|
||||
| `-ae` | apply enhancement (the resulting image is saved to the output directory) |
|
||||
| `-as` | apply scaling |
|
||||
| `-cl` | apply contour detection for curved text lines instead of bounding boxes |
|
||||
| `-ib` | apply binarization (the resulting image is saved to the output directory) |
|
||||
| `-ep` | enable plotting (MUST always be used with `-sl`, `-sd`, `-sa`, `-si` or `-ae`) |
|
||||
| `-eoi` | extract only images to output directory (other processing will not be done) |
|
||||
| `-ho` | ignore headers for reading order dectection |
|
||||
| `-si <directory>` | save image regions detected to this directory |
|
||||
| `-sd <directory>` | save deskewed image to this directory |
|
||||
| `-sl <directory>` | save layout prediction as plot to this directory |
|
||||
| `-sp <directory>` | save cropped page image to this directory |
|
||||
| `-sa <directory>` | save all (plot, enhanced/binary image, layout) to this directory |
|
||||
|
||||
If no option is set, the tool performs layout detection of main regions (background, text, images, separators and marginals).
|
||||
|
||||
The best output quality is produced when RGB images are used as input rather than greyscale or binarized images.
|
||||
|
||||
### `--full-layout` vs `--no-full-layout`
|
||||
|
||||
Here are the difference in elements detected depending on the `--full-layout`/`--no-full-layout` command line flags:
|
||||
|
||||
| | `--full-layout` | `--no-full-layout` |
|
||||
|--------------------------|-----------------|--------------------|
|
||||
| reading order | x | x |
|
||||
| header regions | x | - |
|
||||
| text regions | x | x |
|
||||
| text regions / text line | x | x |
|
||||
| drop-capitals | x | - |
|
||||
| marginals | x | x |
|
||||
| marginals / text line | x | x |
|
||||
| image region | x | x |
|
||||
|
||||
## Use as OCR-D processor
|
||||
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) processor that is described in [`ocrd-tool.json`](https://github.com/qurator-spk/eynollah/tree/main/src/eynollah/ocrd-tool.json).
|
||||
|
||||
The source image file group with (preferably) RGB images should be used as input for Eynollah like this:
|
||||
|
||||
```
|
||||
ocrd-eynollah-segment -I OCR-D-IMG -O SEG-LINE -P models
|
||||
```
|
||||
|
||||
Any image referenced by `@imageFilename` in PAGE-XML is passed on directly to Eynollah as a processor, so that e.g.
|
||||
|
||||
```
|
||||
ocrd-eynollah-segment -I OCR-D-IMG-BIN -O SEG-LINE -P models
|
||||
```
|
||||
|
||||
uses the original (RGB) image despite any binarization that may have occured in previous OCR-D processing steps.
|
||||
|
||||
## Use with Docker
|
||||
TODO
|
||||
|
||||
## Hints
|
||||
* If none of the parameters is set to `true`, the tool will perform a layout detection of main regions (background,
|
||||
text, images, separators and marginals). An advantage of this tool is that it tries to extract main text regions
|
||||
separately as much as possible.
|
||||
|
||||
* If you set `-ae` (**a**llow image **e**nhancement) parameter to `true`, the tool will first check the ppi
|
||||
(pixel-per-inch) of the image and when it is less than 300, the tool will resize it and only then image enhancement will
|
||||
occur. Image enhancement can also take place without this option, but by setting this option to `true`, the layout xml
|
||||
data (e.g. coordinates) will be based on the resized and enhanced image instead of the original image.
|
||||
|
||||
* For some documents, while the quality is good, their scale is very large, and the performance of tool decreases. In
|
||||
such cases you can set `-as` (**a**llow **s**caling) to `true`. With this option enabled, the tool will try to rescale
|
||||
the image and only then the layout detection process will begin.
|
||||
|
||||
* If you care about drop capitals (initials) and headings, you can set `-fl` (**f**ull **l**ayout) to `true`. With this
|
||||
setting, the tool can currently distinguish 7 document layout classes/elements.
|
||||
|
||||
* In cases where the document includes curved headers or curved lines, rectangular bounding boxes for textlines will not
|
||||
be a great option. In such cases it is strongly recommended setting the flag `-cl` (**c**urved **l**ines) to `true` to
|
||||
find contours of curved lines instead of rectangular bounding boxes. Be advised that enabling this option increases the
|
||||
processing time of the tool.
|
||||
|
||||
* To crop and save image regions inside the document, set the parameter `-si` (**s**ave **i**mages) to true and provide
|
||||
a directory path to store the extracted images.
|
||||
|
||||
* To extract only images from a document, set the parameter `-eoi` (**e**xtract **o**nly **i**mages). Choosing this
|
||||
option disables any other processing. To save the cropped images add `-ep` and `-si`.
|
||||
Loading…
Add table
Add a link
Reference in a new issue