mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-08-03 01:12:46 +02:00
add model and training documentation
This commit is contained in:
parent
6f36c7177f
commit
e9fa691308
3 changed files with 783 additions and 11 deletions
17
README.md
17
README.md
|
|
@ -43,10 +43,10 @@ Alternatively, you can run `make install` or `make install-dev` for editable ins
|
|||
## Models
|
||||
Pre-trained models can be downloaded from [qurator-data.de](https://qurator-data.de/eynollah/) or [huggingface](https://huggingface.co/SBB?search_models=eynollah).
|
||||
|
||||
For documentation on methods and models, have a look at [`models.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/models.md).
|
||||
|
||||
## Train
|
||||
🚧 **Work in progress**
|
||||
|
||||
In case you want to train your own model, have a look at [`sbb_pixelwise_segmentation`](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
||||
In case you want to train your own model with Eynollah, have a look at [`train.md`](https://github.com/qurator-spk/eynollah/tree/main/docs/train.md).
|
||||
|
||||
## Usage
|
||||
The command-line interface can be called like this:
|
||||
|
|
@ -83,11 +83,9 @@ If no option is set, the tool performs layout detection of main regions (backgro
|
|||
The best output quality is produced when RGB images are used as input rather than greyscale or binarized images.
|
||||
|
||||
#### Use as OCR-D processor
|
||||
🚧 **Work in progress**
|
||||
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) processor that is described in [`ocrd-tool.json`](https://github.com/qurator-spk/eynollah/tree/main/src/eynollah/ocrd-tool.json).
|
||||
|
||||
Eynollah ships with a CLI interface to be used as [OCR-D](https://ocr-d.de) processor.
|
||||
|
||||
In this case, the source image file group with (preferably) RGB images should be used as input like this:
|
||||
The source image file group with (preferably) RGB images should be used as input for Eynollah like this:
|
||||
|
||||
```
|
||||
ocrd-eynollah-segment -I OCR-D-IMG -O SEG-LINE -P models
|
||||
|
|
@ -99,10 +97,7 @@ Any image referenced by `@imageFilename` in PAGE-XML is passed on directly to Ey
|
|||
ocrd-eynollah-segment -I OCR-D-IMG-BIN -O SEG-LINE -P models
|
||||
```
|
||||
|
||||
uses the original (RGB) image despite any binarization that may have occured in previous OCR-D processing steps
|
||||
|
||||
#### Additional documentation
|
||||
Please check the [wiki](https://github.com/qurator-spk/eynollah/wiki).
|
||||
uses the original (RGB) image despite any binarization that may have occured in previous OCR-D processing steps.
|
||||
|
||||
## How to cite
|
||||
If you find this tool useful in your work, please consider citing our paper:
|
||||
|
|
|
|||
145
docs/models.md
Normal file
145
docs/models.md
Normal file
|
|
@ -0,0 +1,145 @@
|
|||
# Models documentation
|
||||
This suite of 14 models presents a document layout analysis (DLA) system for historical documents implemented by
|
||||
pixel-wise segmentation using a combination of a ResNet50 encoder with various U-Net decoders. In addition, heuristic
|
||||
methods are applied to detect marginals and to determine the reading order of text regions.
|
||||
|
||||
The detection and classification of multiple classes of layout elements such as headings, images, tables etc. as part of
|
||||
DLA is required in order to extract and process them in subsequent steps. Altogether, the combination of image
|
||||
detection, classification and segmentation on the wide variety that can be found in over 400 years of printed cultural
|
||||
heritage makes this a very challenging task. Deep learning models are complemented with heuristics for the detection of
|
||||
text lines, marginals, and reading order. Furthermore, an optional image enhancement step was added in case of documents
|
||||
that either have insufficient pixel density and/or require scaling. Also, a column classifier for the analysis of
|
||||
multi-column documents was added. With these additions, DLA performance was improved, and a high accuracy in the
|
||||
prediction of the reading order is accomplished.
|
||||
|
||||
Two Arabic/Persian terms form the name of the model suite: عين الله, which can be transcribed as "ain'allah" or
|
||||
"eynollah"; it translates into English as "God's Eye" -- it sees (nearly) everything on the document image.
|
||||
|
||||
See the flowchart below for the different stages and how they interact:
|
||||
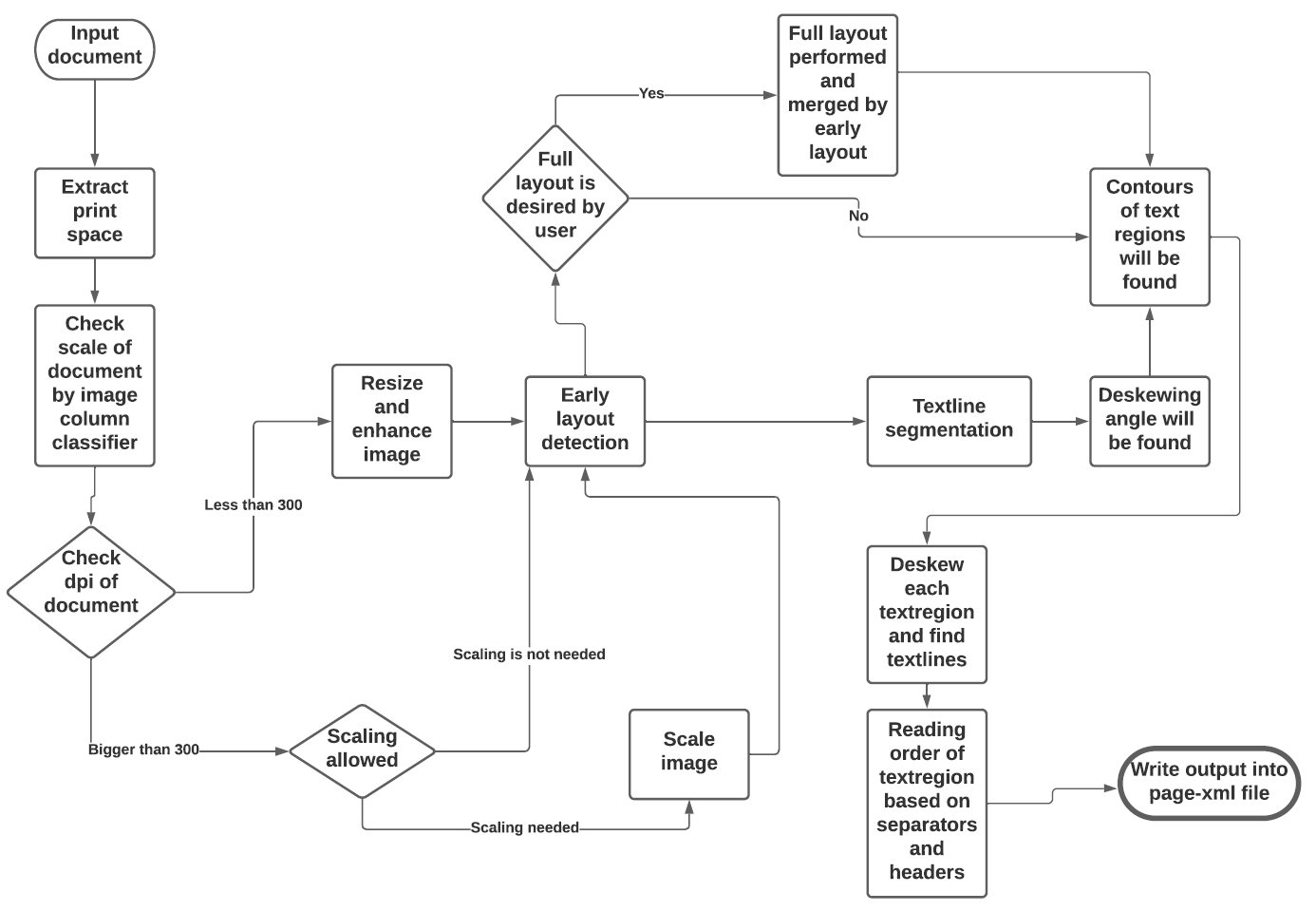
|
||||
|
||||
## Models
|
||||
|
||||
### Image enhancement
|
||||
Model card: [Image Enhancement](https://huggingface.co/SBB/eynollah-enhancement)
|
||||
|
||||
This model addresses image resolution, specifically targeting documents with suboptimal resolution. In instances where
|
||||
the detection of document layout exhibits inadequate performance, the proposed enhancement aims to significantly improve
|
||||
the quality and clarity of the images, thus facilitating enhanced visual interpretation and analysis.
|
||||
|
||||
### Page extraction / border detection
|
||||
Model card: [Page Extraction/Border Detection](https://huggingface.co/SBB/eynollah-page-extraction)
|
||||
|
||||
A problem that can negatively affect OCR are black margins around a page caused by document scanning. A deep learning
|
||||
model helps to crop to the page borders by using a pixel-wise segmentation method.
|
||||
|
||||
### Column classification
|
||||
Model card: [Column Classification](https://huggingface.co/SBB/eynollah-column-classifier)
|
||||
|
||||
This model is a trained classifier that recognizes the number of columns in a document by use of a training set with
|
||||
manual classification of all documents into six classes with either one, two, three, four, five, or six and more columns
|
||||
respectively.
|
||||
|
||||
### Binarization
|
||||
Model card: [Binarization](https://huggingface.co/SBB/eynollah-binarization)
|
||||
|
||||
This model is designed to tackle the intricate task of document image binarization, which involves segmentation of the
|
||||
image into white and black pixels. This process significantly contributes to the overall performance of the layout
|
||||
models, particularly in scenarios where the documents are degraded or exhibit subpar quality. The robust binarization
|
||||
capability of the model enables improved accuracy and reliability in subsequent layout analysis, thereby facilitating
|
||||
enhanced document understanding and interpretation.
|
||||
|
||||
### Main region detection
|
||||
Model card: [Main Region Detection](https://huggingface.co/SBB/eynollah-main-regions)
|
||||
|
||||
This model has employed a different set of labels, including an artificial class specifically designed to encompass the
|
||||
text regions. The inclusion of this artificial class facilitates easier isolation of text regions by the model. This
|
||||
approach grants the advantage of training the model using downscaled images, which in turn leads to faster predictions
|
||||
during the inference phase. By incorporating this methodology, improved efficiency is achieved without compromising the
|
||||
model's ability to accurately identify and classify text regions within documents.
|
||||
|
||||
### Main region detection (with scaling augmentation)
|
||||
Model card: [Main Region Detection (with scaling augmentation)](https://huggingface.co/SBB/eynollah-main-regions-aug-scaling)
|
||||
|
||||
Utilizing scaling augmentation, this model leverages the capability to effectively segment elements of extremely high or
|
||||
low scales within documents. By harnessing this technique, the tool gains a significant advantage in accurately
|
||||
categorizing and isolating such elements, thereby enhancing its overall performance and enabling precise analysis of
|
||||
documents with varying scale characteristics.
|
||||
|
||||
### Main region detection (with rotation augmentation)
|
||||
Model card: [Main Region Detection (with rotation augmentation)](https://huggingface.co/SBB/eynollah-main-regions-aug-rotation)
|
||||
|
||||
This model takes advantage of rotation augmentation. This helps the tool to segment the vertical text regions in a
|
||||
robust way.
|
||||
|
||||
### Main region detection (ensembled)
|
||||
Model card: [Main Region Detection (ensembled)](https://huggingface.co/SBB/eynollah-main-regions-ensembled)
|
||||
|
||||
The robustness of this model is attained through an ensembling technique that combines the weights from various epochs.
|
||||
By employing this approach, the model achieves a high level of resilience and stability, effectively leveraging the
|
||||
strengths of multiple epochs to enhance its overall performance and deliver consistent and reliable results.
|
||||
|
||||
### Full region detection (1,2-column documents)
|
||||
Model card: [Full Region Detection (1,2-column documents)](https://huggingface.co/SBB/eynollah-full-regions-1column)
|
||||
|
||||
This model deals with documents comprising of one and two columns.
|
||||
|
||||
### Full region detection (3,n-column documents)
|
||||
Model card: [Full Region Detection (3,n-column documents)](https://huggingface.co/SBB/eynollah-full-regions-3pluscolumn)
|
||||
|
||||
This model is responsible for detecting headers and drop capitals in documents with three or more columns.
|
||||
|
||||
### Textline detection
|
||||
Model card: [Textline Detection](https://huggingface.co/SBB/eynollah-textline)
|
||||
|
||||
The method for textline detection combines deep learning and heuristics. In the deep learning part, an image-to-image
|
||||
model performs binary segmentation of the document into the classes textline vs. background. In the heuristics part,
|
||||
bounding boxes or contours are derived from binary segmentation.
|
||||
|
||||
Skewed documents can heavily affect textline detection accuracy, so robust deskewing is needed. But detecting textlines
|
||||
with rectangle bounding boxes cannot deal with partially curved textlines. To address this, a functionality
|
||||
specifically for documents with curved textlines was included. After finding the contour of a text region and its
|
||||
corresponding textline segmentation, the text region is cut into smaller vertical straps. For each strap, its textline
|
||||
segmentation is first deskewed and then the textlines are separated with the same heuristic method as for finding
|
||||
textline bounding boxes. Later, the strap is rotated back into its original orientation.
|
||||
|
||||
### Textline detection (light)
|
||||
Model card: [Textline Detection Light (simpler but faster method)](https://huggingface.co/SBB/eynollah-textline_light)
|
||||
|
||||
The method for textline detection combines deep learning and heuristics. In the deep learning part, an image-to-image
|
||||
model performs binary segmentation of the document into the classes textline vs. background. In the heuristics part,
|
||||
bounding boxes or contours are derived from binary segmentation.
|
||||
|
||||
In the context of this textline model, a distinct labeling approach has been employed to ensure accurate predictions.
|
||||
Specifically, an artificial bounding class has been incorporated alongside the textline classes. This strategic
|
||||
inclusion effectively prevents any spurious connections between adjacent textlines during the prediction phase, thereby
|
||||
enhancing the model's ability to accurately identify and delineate individual textlines within documents. This model
|
||||
eliminates the need for additional heuristics in extracting textline contours.
|
||||
|
||||
### Table detection
|
||||
Model card: [Table Detection](https://huggingface.co/SBB/eynollah-tables)
|
||||
|
||||
The objective of this model is to perform table segmentation in historical document images. Due to the pixel-wise
|
||||
segmentation approach employed and the presence of traditional tables predominantly composed of text, the detection of
|
||||
tables required the incorporation of heuristics to achieve reasonable performance. These heuristics were necessary to
|
||||
effectively identify and delineate tables within the historical document images, ensuring accurate segmentation and
|
||||
enabling subsequent analysis and interpretation.
|
||||
|
||||
### Image detection
|
||||
Model card: [Image Detection](https://huggingface.co/SBB/eynollah-image-extraction)
|
||||
|
||||
This model is used for the task of illustration detection only.
|
||||
|
||||
### Reading order detection
|
||||
Model card: [Reading Order Detection]()
|
||||
|
||||
TODO
|
||||
|
||||
## Heuristic methods
|
||||
Additionally, some heuristic methods are employed to further improve the model predictions:
|
||||
* After border detection, the largest contour is determined by a bounding box, and the image cropped to these coordinates.
|
||||
* For text region detection, the image is scaled up to make it easier for the model to detect background space between text regions.
|
||||
* A minimum area is defined for text regions in relation to the overall image dimensions, so that very small regions that are noise can be filtered out.
|
||||
* Deskewing is applied on the text region level (due to regions having different degrees of skew) in order to improve the textline segmentation result.
|
||||
* After deskewing, a calculation of the pixel distribution on the X-axis allows the separation of textlines (foreground) and background pixels.
|
||||
* Finally, using the derived coordinates, bounding boxes are determined for each textline.
|
||||
632
docs/train.md
Normal file
632
docs/train.md
Normal file
|
|
@ -0,0 +1,632 @@
|
|||
# Training documentation
|
||||
This aims to assist users in preparing training datasets, training models, and performing inference with trained models.
|
||||
We cover various use cases including pixel-wise segmentation, image classification, image enhancement, and machine-based
|
||||
reading order detection. For each use case, we provide guidance on how to generate the corresponding training dataset.
|
||||
|
||||
The following three tasks can all be accomplished using the code in the
|
||||
[`train`](https://github.com/qurator-spk/sbb_pixelwise_segmentation/tree/unifying-training-models) directory:
|
||||
|
||||
* generate training dataset
|
||||
* train a model
|
||||
* inference with the trained model
|
||||
|
||||
## Generate training dataset
|
||||
The script `generate_gt_for_training.py` is used for generating training datasets. As the results of the following
|
||||
command demonstrates, the dataset generator provides three different commands:
|
||||
|
||||
`python generate_gt_for_training.py --help`
|
||||
|
||||
These three commands are:
|
||||
|
||||
* image-enhancement
|
||||
* machine-based-reading-order
|
||||
* pagexml2label
|
||||
|
||||
### image-enhancement
|
||||
Generating a training dataset for image enhancement is quite straightforward. All that is needed is a set of
|
||||
high-resolution images. The training dataset can then be generated using the following command:
|
||||
|
||||
`python generate_gt_for_training.py image-enhancement -dis "dir of high resolution images" -dois "dir where degraded
|
||||
images will be written" -dols "dir where the corresponding high resolution image will be written as label" -scs
|
||||
"degrading scales json file"`
|
||||
|
||||
The scales JSON file is a dictionary with a key named 'scales' and values representing scales smaller than 1. Images are
|
||||
downscaled based on these scales and then upscaled again to their original size. This process causes the images to lose
|
||||
resolution at different scales. The degraded images are used as input images, and the original high-resolution images
|
||||
serve as labels. The enhancement model can be trained with this generated dataset. The scales JSON file looks like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"scales": [0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9]
|
||||
}
|
||||
```
|
||||
|
||||
### machine-based-reading-order
|
||||
For machine-based reading order, we aim to determine the reading priority between two sets of text regions. The model's
|
||||
input is a three-channel image: the first and last channels contain information about each of the two text regions,
|
||||
while the middle channel encodes prominent layout elements necessary for reading order, such as separators and headers.
|
||||
To generate the training dataset, our script requires a page XML file that specifies the image layout with the correct
|
||||
reading order.
|
||||
|
||||
For output images, it is necessary to specify the width and height. Additionally, a minimum text region size can be set
|
||||
to filter out regions smaller than this minimum size. This minimum size is defined as the ratio of the text region area
|
||||
to the image area, with a default value of zero. To run the dataset generator, use the following command:
|
||||
|
||||
`python generate_gt_for_training.py machine-based-reading-order -dx "dir of GT xml files" -domi "dir where output images
|
||||
will be written" -docl "dir where the labels will be written" -ih "height" -iw "width" -min "min area ratio"`
|
||||
|
||||
### pagexml2label
|
||||
pagexml2label is designed to generate labels from GT page XML files for various pixel-wise segmentation use cases,
|
||||
including 'layout,' 'textline,' 'printspace,' 'glyph,' and 'word' segmentation.
|
||||
To train a pixel-wise segmentation model, we require images along with their corresponding labels. Our training script
|
||||
expects a PNG image where each pixel corresponds to a label, represented by an integer. The background is always labeled
|
||||
as zero, while other elements are assigned different integers. For instance, if we have ground truth data with four
|
||||
elements including the background, the classes would be labeled as 0, 1, 2, and 3 respectively.
|
||||
|
||||
In binary segmentation scenarios such as textline or page extraction, the background is encoded as 0, and the desired
|
||||
element is automatically encoded as 1 in the PNG label.
|
||||
|
||||
To specify the desired use case and the elements to be extracted in the PNG labels, a custom JSON file can be passed.
|
||||
For example, in the case of 'textline' detection, the JSON file would resemble this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"use_case": "textline"
|
||||
}
|
||||
```
|
||||
|
||||
In the case of layout segmentation a custom config json file can look like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"use_case": "layout",
|
||||
"textregions":{"rest_as_paragraph":1 , "drop-capital": 1, "header":2, "heading":2, "marginalia":3},
|
||||
"imageregion":4,
|
||||
"separatorregion":5,
|
||||
"graphicregions" :{"rest_as_decoration":6 ,"stamp":7}
|
||||
}
|
||||
```
|
||||
|
||||
A possible custom config json file for layout segmentation where the "printspace" is a class:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"use_case": "layout",
|
||||
"textregions":{"rest_as_paragraph":1 , "drop-capital": 1, "header":2, "heading":2, "marginalia":3},
|
||||
"imageregion":4,
|
||||
"separatorregion":5,
|
||||
"graphicregions" :{"rest_as_decoration":6 ,"stamp":7}
|
||||
"printspace_as_class_in_layout" : 8
|
||||
}
|
||||
```
|
||||
|
||||
For the layout use case, it is beneficial to first understand the structure of the page XML file and its elements.
|
||||
In a given image, the annotations of elements are recorded in a page XML file, including their contours and classes.
|
||||
For an image document, the known regions are 'textregion', 'separatorregion', 'imageregion', 'graphicregion',
|
||||
'noiseregion', and 'tableregion'.
|
||||
|
||||
Text regions and graphic regions also have their own specific types. The known types for text regions are 'paragraph',
|
||||
'header', 'heading', 'marginalia', 'drop-capital', 'footnote', 'footnote-continued', 'signature-mark', 'page-number',
|
||||
and 'catch-word'. The known types for graphic regions are 'handwritten-annotation', 'decoration', 'stamp', and
|
||||
'signature'.
|
||||
Since we don't know all types of text and graphic regions, unknown cases can arise. To handle these, we have defined
|
||||
two additional types, "rest_as_paragraph" and "rest_as_decoration", to ensure that no unknown types are missed.
|
||||
This way, users can extract all known types from the labels and be confident that no unknown types are overlooked.
|
||||
|
||||
In the custom JSON file shown above, "header" and "heading" are extracted as the same class, while "marginalia" is shown
|
||||
as a different class. All other text region types, including "drop-capital," are grouped into the same class. For the
|
||||
graphic region, "stamp" has its own class, while all other types are classified together. "Image region" and "separator
|
||||
region" are also present in the label. However, other regions like "noise region" and "table region" will not be
|
||||
included in the label PNG file, even if they have information in the page XML files, as we chose not to include them.
|
||||
|
||||
`python generate_gt_for_training.py pagexml2label -dx "dir of GT xml files" -do "dir where output label png files will
|
||||
be written" -cfg "custom config json file" -to "output type which has 2d and 3d. 2d is used for training and 3d is just
|
||||
to visualise the labels" "`
|
||||
|
||||
We have also defined an artificial class that can be added to the boundary of text region types or text lines. This key
|
||||
is called "artificial_class_on_boundary." If users want to apply this to certain text regions in the layout use case,
|
||||
the example JSON config file should look like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"use_case": "layout",
|
||||
"textregions": {
|
||||
"paragraph": 1,
|
||||
"drop-capital": 1,
|
||||
"header": 2,
|
||||
"heading": 2,
|
||||
"marginalia": 3
|
||||
},
|
||||
"imageregion": 4,
|
||||
"separatorregion": 5,
|
||||
"graphicregions": {
|
||||
"rest_as_decoration": 6
|
||||
},
|
||||
"artificial_class_on_boundary": ["paragraph", "header", "heading", "marginalia"],
|
||||
"artificial_class_label": 7
|
||||
}
|
||||
```
|
||||
|
||||
This implies that the artificial class label, denoted by 7, will be present on PNG files and will only be added to the
|
||||
elements labeled as "paragraph," "header," "heading," and "marginalia."
|
||||
|
||||
For "textline", "word", and "glyph", the artificial class on the boundaries will be activated only if the
|
||||
"artificial_class_label" key is specified in the config file. Its value should be set as 2 since these elements
|
||||
represent binary cases. For example, if the background and textline are denoted as 0 and 1 respectively, then the
|
||||
artificial class should be assigned the value 2. The example JSON config file should look like this for "textline" use
|
||||
case:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"use_case": "textline",
|
||||
"artificial_class_label": 2
|
||||
}
|
||||
```
|
||||
|
||||
If the coordinates of "PrintSpace" or "Border" are present in the page XML ground truth files, and the user wishes to
|
||||
crop only the print space area, this can be achieved by activating the "-ps" argument. However, it should be noted that
|
||||
in this scenario, since cropping will be applied to the label files, the directory of the original images must be
|
||||
provided to ensure that they are cropped in sync with the labels. This ensures that the correct images and labels
|
||||
required for training are obtained. The command should resemble the following:
|
||||
|
||||
`python generate_gt_for_training.py pagexml2label -dx "dir of GT xml files" -do "dir where output label png files will
|
||||
be written" -cfg "custom config json file" -to "output type which has 2d and 3d. 2d is used for training and 3d is just
|
||||
to visualise the labels" -ps -di "dir where the org images are located" -doi "dir where the cropped output images will
|
||||
be written" `
|
||||
|
||||
## Train a model
|
||||
### classification
|
||||
|
||||
For the classification use case, we haven't provided a ground truth generator, as it's unnecessary. For classification,
|
||||
all we require is a training directory with subdirectories, each containing images of its respective classes. We need
|
||||
separate directories for training and evaluation, and the class names (subdirectories) must be consistent across both
|
||||
directories. Additionally, the class names should be specified in the config JSON file, as shown in the following
|
||||
example. If, for instance, we aim to classify "apple" and "orange," with a total of 2 classes, the
|
||||
"classification_classes_name" key in the config file should appear as follows:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "nontransformer",
|
||||
"task": "classification",
|
||||
"n_classes" : 2,
|
||||
"n_epochs" : 10,
|
||||
"input_height" : 448,
|
||||
"input_width" : 448,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 4,
|
||||
"learning_rate": 1e-4,
|
||||
"f1_threshold_classification": 0.8,
|
||||
"pretraining" : true,
|
||||
"classification_classes_name" : {"0":"apple", "1":"orange"},
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
The "dir_train" should be like this:
|
||||
|
||||
```
|
||||
.
|
||||
└── train # train directory
|
||||
├── apple # directory of images for apple class
|
||||
└── orange # directory of images for orange class
|
||||
```
|
||||
|
||||
And the "dir_eval" the same structure as train directory:
|
||||
|
||||
```
|
||||
.
|
||||
└── eval # evaluation directory
|
||||
├── apple # directory of images for apple class
|
||||
└── orange # directory of images for orange class
|
||||
|
||||
```
|
||||
|
||||
The classification model can be trained using the following command line:
|
||||
|
||||
`python train.py with config_classification.json`
|
||||
|
||||
As evident in the example JSON file above, for classification, we utilize a "f1_threshold_classification" parameter.
|
||||
This parameter is employed to gather all models with an evaluation f1 score surpassing this threshold. Subsequently,
|
||||
an ensemble of these model weights is executed, and a model is saved in the output directory as "model_ens_avg".
|
||||
Additionally, the weight of the best model based on the evaluation f1 score is saved as "model_best".
|
||||
|
||||
### reading order
|
||||
An example config json file for machine based reading order should be like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "nontransformer",
|
||||
"task": "reading_order",
|
||||
"n_classes" : 1,
|
||||
"n_epochs" : 5,
|
||||
"input_height" : 672,
|
||||
"input_width" : 448,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 4,
|
||||
"learning_rate": 1e-4,
|
||||
"pretraining" : true,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
The "dir_train" should be like this:
|
||||
|
||||
```
|
||||
.
|
||||
└── train # train directory
|
||||
├── images # directory of images
|
||||
└── labels # directory of labels
|
||||
```
|
||||
|
||||
And the "dir_eval" the same structure as train directory:
|
||||
|
||||
```
|
||||
.
|
||||
└── eval # evaluation directory
|
||||
├── images # directory of images
|
||||
└── labels # directory of labels
|
||||
```
|
||||
|
||||
The classification model can be trained like the classification case command line.
|
||||
|
||||
### Segmentation (Textline, Binarization, Page extraction and layout) and enhancement
|
||||
|
||||
#### Parameter configuration for segmentation or enhancement usecases
|
||||
The following parameter configuration can be applied to all segmentation use cases and enhancements. The augmentation,
|
||||
its sub-parameters, and continued training are defined only for segmentation use cases and enhancements, not for
|
||||
classification and machine-based reading order, as you can see in their example config files.
|
||||
|
||||
* backbone_type: For segmentation tasks (such as text line, binarization, and layout detection) and enhancement, we
|
||||
* offer two backbone options: a "nontransformer" and a "transformer" backbone. For the "transformer" backbone, we first
|
||||
* apply a CNN followed by a transformer. In contrast, the "nontransformer" backbone utilizes only a CNN ResNet-50.
|
||||
* task : The task parameter can have values such as "segmentation", "enhancement", "classification", and "reading_order".
|
||||
* patches: If you want to break input images into smaller patches (input size of the model) you need to set this
|
||||
* parameter to ``true``. In the case that the model should see the image once, like page extraction, patches should be
|
||||
* set to ``false``.
|
||||
* n_batch: Number of batches at each iteration.
|
||||
* n_classes: Number of classes. In the case of binary classification this should be 2. In the case of reading_order it
|
||||
* should set to 1. And for the case of layout detection just the unique number of classes should be given.
|
||||
* n_epochs: Number of epochs.
|
||||
* input_height: This indicates the height of model's input.
|
||||
* input_width: This indicates the width of model's input.
|
||||
* weight_decay: Weight decay of l2 regularization of model layers.
|
||||
* pretraining: Set to ``true`` to load pretrained weights of ResNet50 encoder. The downloaded weights should be saved
|
||||
* in a folder named "pretrained_model" in the same directory of "train.py" script.
|
||||
* augmentation: If you want to apply any kind of augmentation this parameter should first set to ``true``.
|
||||
* flip_aug: If ``true``, different types of filp will be applied on image. Type of flips is given with "flip_index" parameter.
|
||||
* blur_aug: If ``true``, different types of blurring will be applied on image. Type of blurrings is given with "blur_k" parameter.
|
||||
* scaling: If ``true``, scaling will be applied on image. Scale of scaling is given with "scales" parameter.
|
||||
* degrading: If ``true``, degrading will be applied to the image. The amount of degrading is defined with "degrade_scales" parameter.
|
||||
* brightening: If ``true``, brightening will be applied to the image. The amount of brightening is defined with "brightness" parameter.
|
||||
* rotation_not_90: If ``true``, rotation (not 90 degree) will be applied on image. Rotation angles are given with "thetha" parameter.
|
||||
* rotation: If ``true``, 90 degree rotation will be applied on image.
|
||||
* binarization: If ``true``,Otsu thresholding will be applied to augment the input data with binarized images.
|
||||
* scaling_bluring: If ``true``, combination of scaling and blurring will be applied on image.
|
||||
* scaling_binarization: If ``true``, combination of scaling and binarization will be applied on image.
|
||||
* scaling_flip: If ``true``, combination of scaling and flip will be applied on image.
|
||||
* flip_index: Type of flips.
|
||||
* blur_k: Type of blurrings.
|
||||
* scales: Scales of scaling.
|
||||
* brightness: The amount of brightenings.
|
||||
* thetha: Rotation angles.
|
||||
* degrade_scales: The amount of degradings.
|
||||
* continue_training: If ``true``, it means that you have already trained a model and you would like to continue the training. So it is needed to provide the dir of trained model with "dir_of_start_model" and index for naming the models. For example if you have already trained for 3 epochs then your last index is 2 and if you want to continue from model_1.h5, you can set ``index_start`` to 3 to start naming model with index 3.
|
||||
* weighted_loss: If ``true``, this means that you want to apply weighted categorical_crossentropy as loss fucntion. Be carefull if you set to ``true``the parameter "is_loss_soft_dice" should be ``false``
|
||||
* data_is_provided: If you have already provided the input data you can set this to ``true``. Be sure that the train and eval data are in "dir_output". Since when once we provide training data we resize and augment them and then we write them in sub-directories train and eval in "dir_output".
|
||||
* dir_train: This is the directory of "images" and "labels" (dir_train should include two subdirectories with names of images and labels ) for raw images and labels. Namely they are not prepared (not resized and not augmented) yet for training the model. When we run this tool these raw data will be transformed to suitable size needed for the model and they will be written in "dir_output" in train and eval directories. Each of train and eval include "images" and "labels" sub-directories.
|
||||
* index_start: Starting index for saved models in the case that "continue_training" is ``true``.
|
||||
* dir_of_start_model: Directory containing pretrained model to continue training the model in the case that "continue_training" is ``true``.
|
||||
* transformer_num_patches_xy: Number of patches for vision transformer in x and y direction respectively.
|
||||
* transformer_patchsize_x: Patch size of vision transformer patches in x direction.
|
||||
* transformer_patchsize_y: Patch size of vision transformer patches in y direction.
|
||||
* transformer_projection_dim: Transformer projection dimension. Default value is 64.
|
||||
* transformer_mlp_head_units: Transformer Multilayer Perceptron (MLP) head units. Default value is [128, 64].
|
||||
* transformer_layers: transformer layers. Default value is 8.
|
||||
* transformer_num_heads: Transformer number of heads. Default value is 4.
|
||||
* transformer_cnn_first: We have two types of vision transformers. In one type, a CNN is applied first, followed by a transformer. In the other type, this order is reversed. If transformer_cnn_first is true, it means the CNN will be applied before the transformer. Default value is true.
|
||||
|
||||
In the case of segmentation and enhancement the train and evaluation directory should be as following.
|
||||
|
||||
The "dir_train" should be like this:
|
||||
|
||||
```
|
||||
.
|
||||
└── train # train directory
|
||||
├── images # directory of images
|
||||
└── labels # directory of labels
|
||||
```
|
||||
|
||||
And the "dir_eval" the same structure as train directory:
|
||||
|
||||
```
|
||||
.
|
||||
└── eval # evaluation directory
|
||||
├── images # directory of images
|
||||
└── labels # directory of labels
|
||||
```
|
||||
|
||||
After configuring the JSON file for segmentation or enhancement, training can be initiated by running the following
|
||||
command, similar to the process for classification and reading order:
|
||||
|
||||
`python train.py with config_classification.json`
|
||||
|
||||
#### Binarization
|
||||
An example config json file for binarization can be like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "transformer",
|
||||
"task": "binarization",
|
||||
"n_classes" : 2,
|
||||
"n_epochs" : 4,
|
||||
"input_height" : 224,
|
||||
"input_width" : 672,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 1,
|
||||
"learning_rate": 1e-4,
|
||||
"patches" : true,
|
||||
"pretraining" : true,
|
||||
"augmentation" : true,
|
||||
"flip_aug" : false,
|
||||
"blur_aug" : false,
|
||||
"scaling" : true,
|
||||
"degrading": false,
|
||||
"brightening": false,
|
||||
"binarization" : false,
|
||||
"scaling_bluring" : false,
|
||||
"scaling_binarization" : false,
|
||||
"scaling_flip" : false,
|
||||
"rotation": false,
|
||||
"rotation_not_90": false,
|
||||
"transformer_num_patches_xy": [7, 7],
|
||||
"transformer_patchsize_x": 3,
|
||||
"transformer_patchsize_y": 1,
|
||||
"transformer_projection_dim": 192,
|
||||
"transformer_mlp_head_units": [128, 64],
|
||||
"transformer_layers": 8,
|
||||
"transformer_num_heads": 4,
|
||||
"transformer_cnn_first": true,
|
||||
"blur_k" : ["blur","guass","median"],
|
||||
"scales" : [0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.4],
|
||||
"brightness" : [1.3, 1.5, 1.7, 2],
|
||||
"degrade_scales" : [0.2, 0.4],
|
||||
"flip_index" : [0, 1, -1],
|
||||
"thetha" : [10, -10],
|
||||
"continue_training": false,
|
||||
"index_start" : 0,
|
||||
"dir_of_start_model" : " ",
|
||||
"weighted_loss": false,
|
||||
"is_loss_soft_dice": false,
|
||||
"data_is_provided": false,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
#### Textline
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "nontransformer",
|
||||
"task": "segmentation",
|
||||
"n_classes" : 2,
|
||||
"n_epochs" : 4,
|
||||
"input_height" : 448,
|
||||
"input_width" : 224,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 1,
|
||||
"learning_rate": 1e-4,
|
||||
"patches" : true,
|
||||
"pretraining" : true,
|
||||
"augmentation" : true,
|
||||
"flip_aug" : false,
|
||||
"blur_aug" : false,
|
||||
"scaling" : true,
|
||||
"degrading": false,
|
||||
"brightening": false,
|
||||
"binarization" : false,
|
||||
"scaling_bluring" : false,
|
||||
"scaling_binarization" : false,
|
||||
"scaling_flip" : false,
|
||||
"rotation": false,
|
||||
"rotation_not_90": false,
|
||||
"blur_k" : ["blur","guass","median"],
|
||||
"scales" : [0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.4],
|
||||
"brightness" : [1.3, 1.5, 1.7, 2],
|
||||
"degrade_scales" : [0.2, 0.4],
|
||||
"flip_index" : [0, 1, -1],
|
||||
"thetha" : [10, -10],
|
||||
"continue_training": false,
|
||||
"index_start" : 0,
|
||||
"dir_of_start_model" : " ",
|
||||
"weighted_loss": false,
|
||||
"is_loss_soft_dice": false,
|
||||
"data_is_provided": false,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
#### Enhancement
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "nontransformer",
|
||||
"task": "enhancement",
|
||||
"n_classes" : 3,
|
||||
"n_epochs" : 4,
|
||||
"input_height" : 448,
|
||||
"input_width" : 224,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 4,
|
||||
"learning_rate": 1e-4,
|
||||
"patches" : true,
|
||||
"pretraining" : true,
|
||||
"augmentation" : true,
|
||||
"flip_aug" : false,
|
||||
"blur_aug" : false,
|
||||
"scaling" : true,
|
||||
"degrading": false,
|
||||
"brightening": false,
|
||||
"binarization" : false,
|
||||
"scaling_bluring" : false,
|
||||
"scaling_binarization" : false,
|
||||
"scaling_flip" : false,
|
||||
"rotation": false,
|
||||
"rotation_not_90": false,
|
||||
"blur_k" : ["blur","guass","median"],
|
||||
"scales" : [0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.4],
|
||||
"brightness" : [1.3, 1.5, 1.7, 2],
|
||||
"degrade_scales" : [0.2, 0.4],
|
||||
"flip_index" : [0, 1, -1],
|
||||
"thetha" : [10, -10],
|
||||
"continue_training": false,
|
||||
"index_start" : 0,
|
||||
"dir_of_start_model" : " ",
|
||||
"weighted_loss": false,
|
||||
"is_loss_soft_dice": false,
|
||||
"data_is_provided": false,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
It's important to mention that the value of n_classes for enhancement should be 3, as the model's output is a 3-channel
|
||||
image.
|
||||
|
||||
#### Page extraction
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "nontransformer",
|
||||
"task": "segmentation",
|
||||
"n_classes" : 2,
|
||||
"n_epochs" : 4,
|
||||
"input_height" : 448,
|
||||
"input_width" : 224,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 1,
|
||||
"learning_rate": 1e-4,
|
||||
"patches" : false,
|
||||
"pretraining" : true,
|
||||
"augmentation" : false,
|
||||
"flip_aug" : false,
|
||||
"blur_aug" : false,
|
||||
"scaling" : true,
|
||||
"degrading": false,
|
||||
"brightening": false,
|
||||
"binarization" : false,
|
||||
"scaling_bluring" : false,
|
||||
"scaling_binarization" : false,
|
||||
"scaling_flip" : false,
|
||||
"rotation": false,
|
||||
"rotation_not_90": false,
|
||||
"blur_k" : ["blur","guass","median"],
|
||||
"scales" : [0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.4],
|
||||
"brightness" : [1.3, 1.5, 1.7, 2],
|
||||
"degrade_scales" : [0.2, 0.4],
|
||||
"flip_index" : [0, 1, -1],
|
||||
"thetha" : [10, -10],
|
||||
"continue_training": false,
|
||||
"index_start" : 0,
|
||||
"dir_of_start_model" : " ",
|
||||
"weighted_loss": false,
|
||||
"is_loss_soft_dice": false,
|
||||
"data_is_provided": false,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
|
||||
For page segmentation (or printspace or border segmentation), the model needs to view the input image in its entirety,
|
||||
hence the patches parameter should be set to false.
|
||||
|
||||
#### layout segmentation
|
||||
An example config json file for layout segmentation with 5 classes (including background) can be like this:
|
||||
|
||||
```yaml
|
||||
{
|
||||
"backbone_type" : "transformer",
|
||||
"task": "segmentation",
|
||||
"n_classes" : 5,
|
||||
"n_epochs" : 4,
|
||||
"input_height" : 448,
|
||||
"input_width" : 224,
|
||||
"weight_decay" : 1e-6,
|
||||
"n_batch" : 1,
|
||||
"learning_rate": 1e-4,
|
||||
"patches" : true,
|
||||
"pretraining" : true,
|
||||
"augmentation" : true,
|
||||
"flip_aug" : false,
|
||||
"blur_aug" : false,
|
||||
"scaling" : true,
|
||||
"degrading": false,
|
||||
"brightening": false,
|
||||
"binarization" : false,
|
||||
"scaling_bluring" : false,
|
||||
"scaling_binarization" : false,
|
||||
"scaling_flip" : false,
|
||||
"rotation": false,
|
||||
"rotation_not_90": false,
|
||||
"transformer_num_patches_xy": [7, 14],
|
||||
"transformer_patchsize_x": 1,
|
||||
"transformer_patchsize_y": 1,
|
||||
"transformer_projection_dim": 64,
|
||||
"transformer_mlp_head_units": [128, 64],
|
||||
"transformer_layers": 8,
|
||||
"transformer_num_heads": 4,
|
||||
"transformer_cnn_first": true,
|
||||
"blur_k" : ["blur","guass","median"],
|
||||
"scales" : [0.6, 0.7, 0.8, 0.9, 1.1, 1.2, 1.4],
|
||||
"brightness" : [1.3, 1.5, 1.7, 2],
|
||||
"degrade_scales" : [0.2, 0.4],
|
||||
"flip_index" : [0, 1, -1],
|
||||
"thetha" : [10, -10],
|
||||
"continue_training": false,
|
||||
"index_start" : 0,
|
||||
"dir_of_start_model" : " ",
|
||||
"weighted_loss": false,
|
||||
"is_loss_soft_dice": false,
|
||||
"data_is_provided": false,
|
||||
"dir_train": "./train",
|
||||
"dir_eval": "./eval",
|
||||
"dir_output": "./output"
|
||||
}
|
||||
```
|
||||
## Inference with the trained model
|
||||
|
||||
### classification
|
||||
For conducting inference with a trained model, you simply need to execute the following command line, specifying the
|
||||
directory of the model and the image on which to perform inference:
|
||||
|
||||
`python inference.py -m "model dir" -i "image" `
|
||||
|
||||
This will straightforwardly return the class of the image.
|
||||
|
||||
### machine based reading order
|
||||
To infer the reading order using a reading order model, we need a page XML file containing layout information but
|
||||
without the reading order. We simply need to provide the model directory, the XML file, and the output directory.
|
||||
The new XML file with the added reading order will be written to the output directory with the same name.
|
||||
We need to run:
|
||||
|
||||
`python inference.py -m "model dir" -xml "page xml file" -o "output dir to write new xml with reading order" `
|
||||
|
||||
### Segmentation (Textline, Binarization, Page extraction and layout) and enhancement
|
||||
For conducting inference with a trained model for segmentation and enhancement you need to run the following command
|
||||
line:
|
||||
|
||||
`python inference.py -m "model dir" -i "image" -p -s "output image" `
|
||||
|
||||
Note that in the case of page extraction the -p flag is not needed.
|
||||
|
||||
For segmentation or binarization tasks, if a ground truth (GT) label is available, the IoU evaluation metric can be
|
||||
calculated for the output. To do this, you need to provide the GT label using the argument -gt.
|
||||
Loading…
Add table
Add a link
Reference in a new issue