mirror of
https://github.com/qurator-spk/eynollah.git
synced 2026-07-12 06:39:31 +02:00
add flowchart
This commit is contained in:
parent
156b0db519
commit
41d6ddeae8
1 changed files with 3 additions and 1 deletions
|
|
@ -18,7 +18,7 @@ It can currently detect the following layout classes/elements:
|
||||||
|
|
||||||
In addition, the tool can be used to detect the _Reading Order_ of regions. The final goal is to feed the output to an OCR model.
|
In addition, the tool can be used to detect the _Reading Order_ of regions. The final goal is to feed the output to an OCR model.
|
||||||
|
|
||||||
The tool uses a combination of various models and heuristics:
|
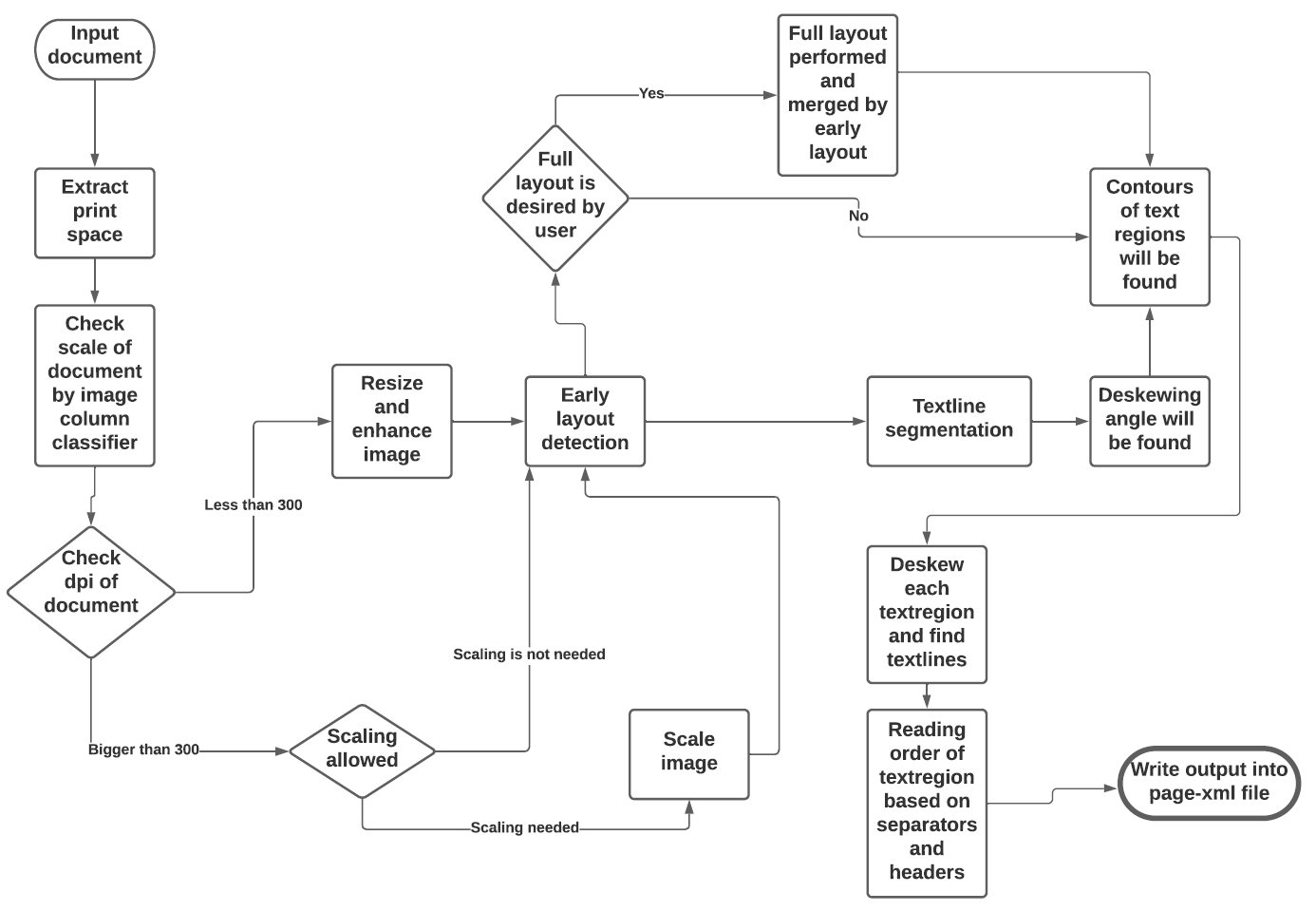
The tool uses a combination of various models and heuristics (see flowchart below for the different stages and how they interact):
|
||||||
* [Border detection](https://github.com/qurator-spk/eynollah#border-detection)
|
* [Border detection](https://github.com/qurator-spk/eynollah#border-detection)
|
||||||
* [Layout detection](https://github.com/qurator-spk/eynollah#layout-detection)
|
* [Layout detection](https://github.com/qurator-spk/eynollah#layout-detection)
|
||||||
* [Textline detection](https://github.com/qurator-spk/eynollah#textline-detection)
|
* [Textline detection](https://github.com/qurator-spk/eynollah#textline-detection)
|
||||||
|
|
@ -28,6 +28,8 @@ The tool uses a combination of various models and heuristics:
|
||||||
|
|
||||||
The first three stages are based on [pixelwise segmentation](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
The first three stages are based on [pixelwise segmentation](https://github.com/qurator-spk/sbb_pixelwise_segmentation).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Border detection
|
## Border detection
|
||||||
For the purpose of text recognition (OCR) and in order to avoid noise being introduced from texts outside the printspace, one first needs to detect the border of the printed frame. This is done by a binary pixelwise-segmentation model trained on a dataset of 2,000 documents where about 1,200 of them come from the [dhSegment](https://github.com/dhlab-epfl/dhSegment/) project (you can download the dataset from [here](https://github.com/dhlab-epfl/dhSegment/releases/download/v0.2/pages.zip)) and the remainder having been annotated in SBB. For border detection, the model needs to be fed with the whole image at once rather than separated in patches.
|
For the purpose of text recognition (OCR) and in order to avoid noise being introduced from texts outside the printspace, one first needs to detect the border of the printed frame. This is done by a binary pixelwise-segmentation model trained on a dataset of 2,000 documents where about 1,200 of them come from the [dhSegment](https://github.com/dhlab-epfl/dhSegment/) project (you can download the dataset from [here](https://github.com/dhlab-epfl/dhSegment/releases/download/v0.2/pages.zip)) and the remainder having been annotated in SBB. For border detection, the model needs to be fed with the whole image at once rather than separated in patches.
|
||||||
|
|
||||||
|
|
|
||||||
Loading…
Add table
Add a link
Reference in a new issue