| .screenshots | ||
| doc | ||
| qurator | ||
| .dockerignore | ||
| __init__.py | ||
| Dockerfile | ||
| Dockerfile.cpu | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| requirements.txt | ||
| setup.py | ||
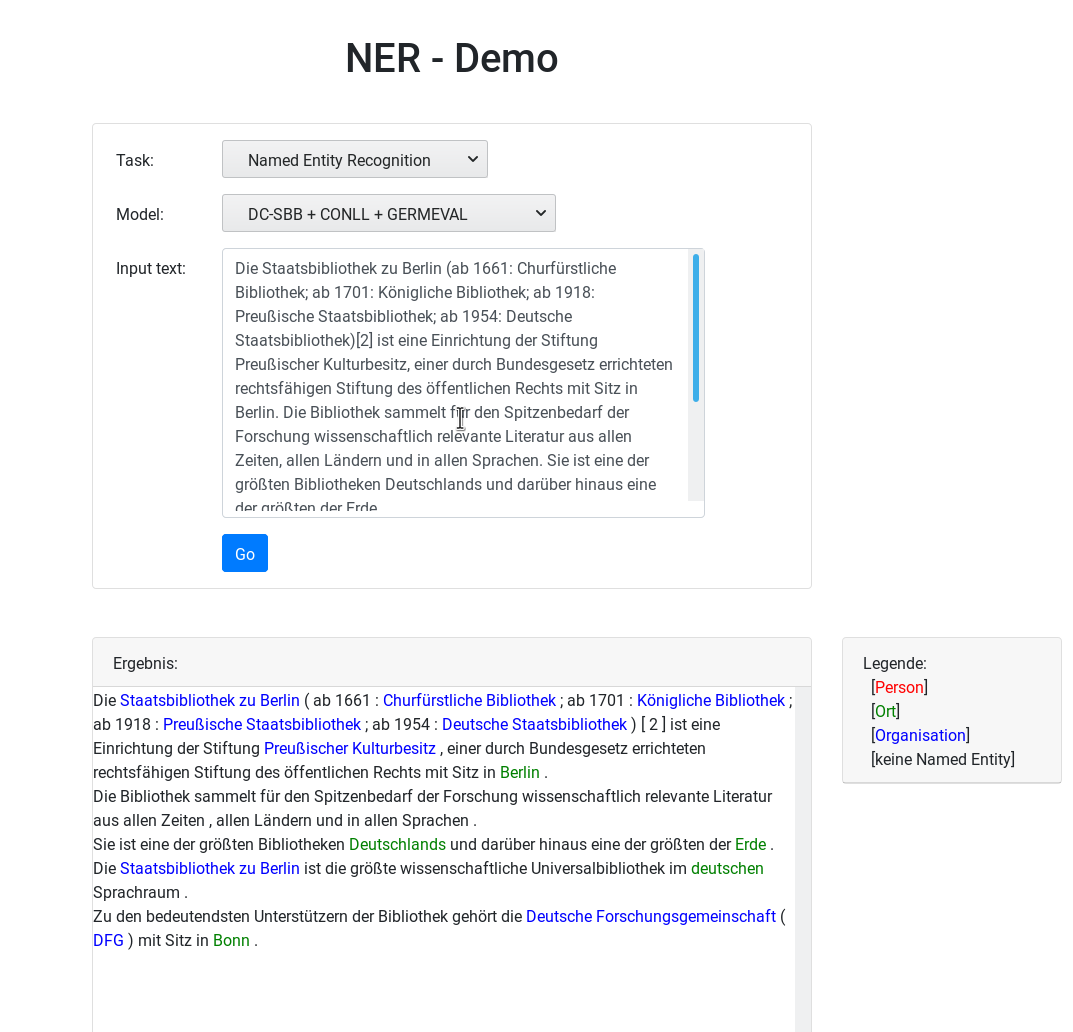
How the models have been obtained is described in our paper.
Installation:
Setup virtual environment:
virtualenv --python=python3.6 venv
Activate virtual environment:
source venv/bin/activate
Upgrade pip:
pip install -U pip
Install package together with its dependencies in development mode:
pip install -e ./
Download required models: https://qurator-data.de/sbb_ner/models.tar.gz
Extract model archive:
tar -xzf models.tar.gz
Run webapp directly:
env FLASK_APP=qurator/sbb_ner/webapp/app.py env FLASK_ENV=development env USE_CUDA=True flask run --host=0.0.0.0
Set USE_CUDA=False, if you do not have a GPU available/installed.
For production purposes rather use
env USE_CUDA=True/False gunicorn --bind 0.0.0.0:5000 qurator.sbb_ner.webapp.wsgi:app
If you want to use a different model configuration file:
env USE_CUDA=True/False env CONFIG=`realpath ./my-config.json` gunicorn --bind 0.0.0.0:5000 qurator.sbb_ner.webapp.wsgi:app
Docker
CPU-only:
docker build --build-arg http_proxy=$http_proxy -t qurator/webapp-ner-cpu -f Dockerfile.cpu .
docker run -ti --rm=true --mount type=bind,source=data/konvens2019,target=/usr/src/qurator-sbb-ner/data/konvens2019 -p 5000:5000 qurator/webapp-ner-cpu
GPU:
Make sure that your GPU is correctly set up and that nvidia-docker has been installed.
docker build --build-arg http_proxy=$http_proxy -t qurator/webapp-ner-gpu -f Dockerfile .
docker run -ti --rm=true --mount type=bind,source=data/konvens2019,target=/usr/src/qurator-sbb-ner/data/konvens2019 -p 5000:5000 qurator/webapp-ner-gpu
NER web-interface is availabe at http://localhost:5000 .
REST - Interface
Get available models:
curl http://localhost:5000/models
Output:
[
{
"default": true,
"id": 1,
"model_dir": "data/konvens2019/build-wd_0.03/bert-all-german-de-finetuned",
"name": "DC-SBB + CONLL + GERMEVAL"
},
{
"default": false,
"id": 2,
"model_dir": "data/konvens2019/build-on-all-german-de-finetuned/bert-sbb-de-finetuned",
"name": "DC-SBB + CONLL + GERMEVAL + SBB"
},
{
"default": false,
"id": 3,
"model_dir": "data/konvens2019/build-wd_0.03/bert-sbb-de-finetuned",
"name": "DC-SBB + SBB"
},
{
"default": false,
"id": 4,
"model_dir": "data/konvens2019/build-wd_0.03/bert-all-german-baseline",
"name": "CONLL + GERMEVAL"
}
]
Perform NER using model 1:
curl -d '{ "text": "Paris Hilton wohnt im Hilton Paris in Paris." }' -H "Content-Type: application/json" http://localhost:5000/ner/1
Output:
[
[
{
"prediction": "B-PER",
"word": "Paris"
},
{
"prediction": "I-PER",
"word": "Hilton"
},
{
"prediction": "O",
"word": "wohnt"
},
{
"prediction": "O",
"word": "im"
},
{
"prediction": "B-ORG",
"word": "Hilton"
},
{
"prediction": "I-ORG",
"word": "Paris"
},
{
"prediction": "O",
"word": "in"
},
{
"prediction": "B-LOC",
"word": "Paris"
},
{
"prediction": "O",
"word": "."
}
]
]
The JSON above is the expected input format of the SBB named entity linking and disambiguation system.
Model-Training
Preprocessing of NER ground-truth:
compile_conll
Read CONLL 2003 ner ground truth files from directory and write the outcome of the data parsing to some pandas DataFrame that is stored as pickle.
Usage
compile_conll --help
compile_germ_eval
Read germ eval .tsv files from directory and write the outcome of the data parsing to some pandas DataFrame that is stored as pickle.
Usage
compile_germ_eval --help
compile_europeana_historic
Read europeana historic ner ground truth .bio files from directory and write the outcome of the data parsing to some pandas DataFrame that is stored as pickle.
Usage
compile_europeana_historic --help
compile_wikiner
Read wikiner files from directory and write the outcome of the data parsing to some pandas DataFrame that is stored as pickle.
Usage
compile_wikiner --help
Train BERT - NER model:
bert-ner
Perform BERT for NER supervised training and test/cross-validation.
Usage
bert-ner --help
BERT-Pre-training:
collectcorpus
collectcorpus --help
Usage: collectcorpus [OPTIONS] FULLTEXT_FILE SELECTION_FILE CORPUS_FILE
Reads the fulltext from a CSV or SQLITE3 file (see also altotool) and
write it to one big text file.
FULLTEXT_FILE: The CSV or SQLITE3 file to read from.
SELECTION_FILE: Consider only a subset of all pages that is defined by the
DataFrame that is stored in <selection_file>.
CORPUS_FILE: The output file that can be used by bert-pregenerate-trainingdata.
Options:
--chunksize INTEGER Process the corpus in chunks of <chunksize>.
default:10**4
--processes INTEGER Number of parallel processes. default: 6
--min-line-len INTEGER Lower bound of line length in output file.
default:80
--help Show this message and exit.
bert-pregenerate-trainingdata
Generate data for BERT pre-training from a corpus text file where the documents are separated by an empty line (output of corpuscollect).
Usage
bert-pregenerate-trainingdata --help
bert-finetune
Perform BERT pre-training on pre-generated data.
Usage
bert-finetune --help